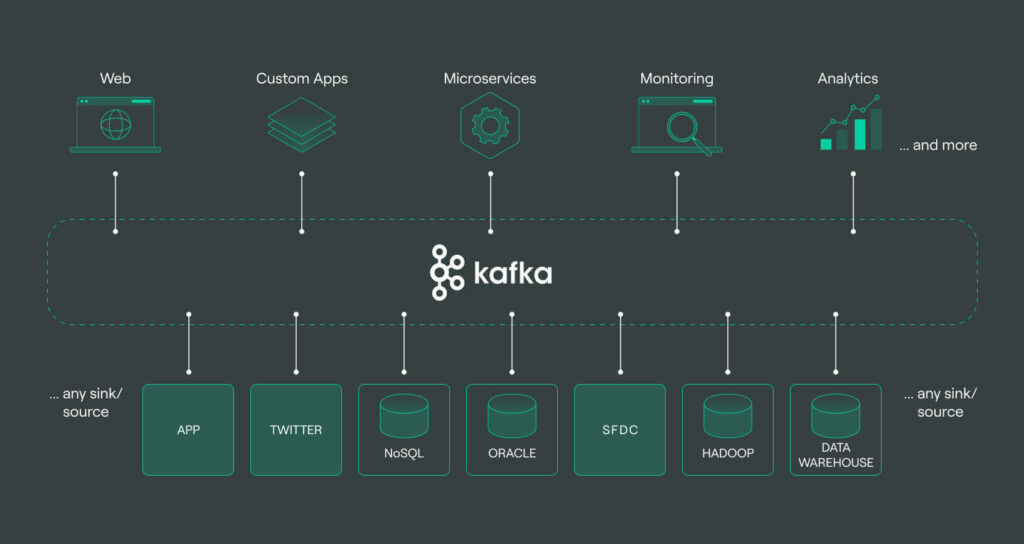
Kafka is an open-source distributed event streaming platform that is designed to handle real-time data streams at scale. It serves as a highly reliable, fault-tolerant messaging system that can be used to publish and subscribe to streams of records, allowing for efficient data processing in real-time. Kafka’s architecture enables it to handle high volumes of data from various sources and process it in a distributed manner, making it a powerful tool for powering real-time Big Data applications. By providing a seamless way to ingest, store, and analyze massive amounts of data in real-time, Kafka has become a critical component in the Big Data ecosystem, enabling organizations to make timely, data-driven decisions and derive valuable insights from their data streams.
Apache Kafka is an open-source distributed event streaming platform designed to handle high-throughput data streams in real time. Originally developed at LinkedIn and later donated to the Apache Software Foundation, Kafka has emerged as a cornerstone technology in the world of Big Data due to its ability to process large volumes of data efficiently. In this article, we delve into the intricacies of Kafka, its architecture, and how it supports real-time big data applications.
Understanding Kafka’s Architecture
At its core, Kafka operates as a messaging system that decouples data producers from data consumers, facilitating seamless data flow. The architecture comprises several key components:
- Producers: Producers are applications that send data to Kafka. They publish messages to various topics, acting as the source of data.
- Topics: A topic is a stream of records, categorized by a unique name. Producers push data into these topics.
- Consumers: Consumers read data from topics. They can be individual services or applications that need to process streaming data.
- Brokers: A Kafka cluster consists of multiple brokers that store data and serve clients, with each broker handling a subset of the overall topics.
- Zookeeper: Zookeeper is used for coordinating and managing the Kafka brokers, handling metadata and leader election among brokers.
Key Features of Kafka
Kafka offers several features that empower developers to build robust real-time applications:
- Scalability: Kafka can effortlessly scale horizontally by adding more brokers and partitions, allowing organizations to accommodate growing data needs.
- Durability: Data in Kafka is replicated across multiple brokers, ensuring no data loss and providing fault tolerance.
- Low Latency: Kafka is optimized for low-latency message delivery, making it suitable for real-time processing of data streams.
- High Throughput: Kafka can handle millions of messages per second, enabling high-volume data processing without degradation of performance.
- Stream Processing: Kafka’s Streams API allows developers to perform real-time transformations and computations on the data.
How Kafka Facilitates Real-Time Data Processing
Kafka’s design principles make it an ideal choice for real-time data processing applications. Here are some ways in which it facilitates this:
1. Decoupling of Data Producers and Consumers
Kafka uses a publish-subscribe model that allows data producers and consumers to operate independently. This decoupling means that a producer can continue to send data even if the consumer is temporarily down. Additionally, multiple consumers can process the same data concurrently, allowing for scalable architectures.
2. Data Retention and Replayability
Kafka retains messages for a configurable duration, which enables consumers to retrieve data at any time within that window. This feature allows for data replay, making it easy to reprocess data under different conditions or when corrections are necessary.
3. Stream Processing with Kafka Streams
Kafka Streams provides a powerful library for real-time stream processing. It allows developers to create applications that can read from one or more Kafka topics, process the data (e.g., filtering, aggregating), and write the results to another stream. This capability is essential for scenarios such as real-time analytics and monitoring.
4. Event Sourcing
Kafka serves as an ideal backbone for event sourcing architectures. In event sourcing, application state is determined by the sequence of events that have occurred rather than by the current state of the data. Kafka’s ability to store and replay events makes it a natural fit for this paradigm.
5. Integration with Data Ecosystem
Kafka integrates seamlessly with other technologies commonly used in the Big Data landscape. For example, it can connect to Apache Spark for real-time analysis, Hadoop for batch processing, and various cloud platforms such as AWS and Google Cloud for modernization efforts.
Use Cases of Kafka in Real-Time Big Data Applications
Here are several key use cases demonstrating how Kafka powers real-time Big Data applications:
1. Log Aggregation
Kafka is commonly used for log aggregation, where logs are collected from various sources such as application servers, microservices, and hardware devices. By centralizing logs into Kafka, organizations can streamline alerting, monitoring, and analytics efforts.
2. Real-Time Analytics
With Kafka, businesses can perform real-time analytics, processing incoming data streams to derive insights almost instantaneously. This is crucial for applications such as fraud detection, recommendation systems, and operational monitoring.
3. Data Integration Pipelines
Kafka functions as a powerful backbone for data integration pipelines. It facilitates the movement of data from disparate sources into centralized locations (like data lakes and warehouses) where further processing occurs.
4. Event-Driven Microservices
Kafka is widely used in microservice architectures to allow services to communicate through asynchronous events. This promotes a loosely-coupled architecture where individual services can evolve independently while still remaining synchronized.
5. Internet of Things (IoT)
In IoT applications, Kafka can ingest and process large volumes of data from connected devices. It allows the aggregation of data streams from sensors, enabling real-time monitoring, alerts, and analytics.
Kafka’s Ecosystem
Kafka is part of a broader ecosystem that enhances its capabilities:
- Kafka Connect: A framework for connecting Kafka with other systems (like databases, key-value stores, and file systems) to move data in and out.
- Kafka Streams: A client library for building applications that process data stored in Kafka.
- KSQL: A SQL-like language for querying data streams in real-time, simplifying stream processing and making it accessible to non-programmers.
- Schema Registry: A service for managing and enforcing data schemas, ensuring compatibility and data integrity across different applications.
Best Practices for Implementing Kafka
When deploying Kafka for real-time big data applications, consider the following best practices:
- Plan Topic Design: Thoughtful topic design is crucial. Determine partition counts based on data volume and consumer capabilities to maximize throughput.
- Monitor and Manage Failures: Implement monitoring tools to keep track of broker health and consumer lag, enabling quick identification and resolution of issues.
- Optimize Performance: Tune Kafka configurations based on workloads, including batching, compression, and producer settings.
- Ensure Data Security: Use SSL/TLS for data encryption and authentication—this is crucial in environments handling sensitive data.
- Test for Scalability: Regularly conduct capacity tests to ensure that the Kafka deployment can handle anticipated growth in data volumes.
Kafka is a high-throughput, fault-tolerant platform that effectively processes real-time data streams, making it a powerful tool in the realm of Big Data applications. Its ability to efficiently handle large volumes of data and provide real-time analytics makes it a crucial component for organizations looking to harness and leverage Big Data for decision-making and insights. Kafka’s versatility and scalability make it a valuable asset for building robust and efficient data pipelines in today’s data-driven world.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 How Elasticsearch is Used in Big Data Applications
How Elasticsearch is Used in Big Data Applications
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models