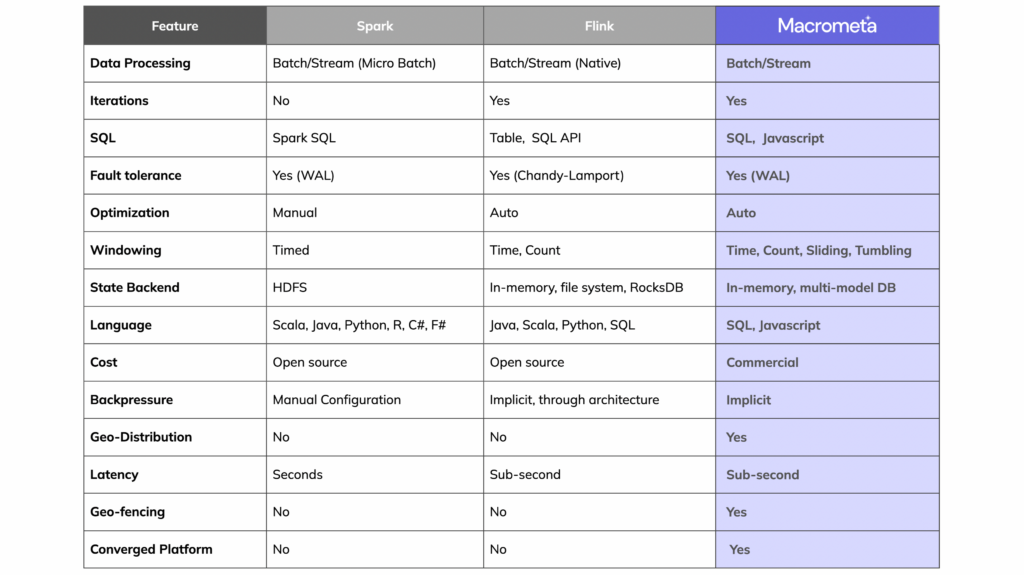
Apache Flink and Apache Spark are two popular open-source Big Data processing frameworks known for their powerful capabilities in handling large-scale data processing tasks. While both frameworks offer high performance and scalability, there are key differences that set them apart. In this comparison, we will delve into the strengths and weaknesses of Apache Flink and Apache Spark to determine which one is better suited for specific Big Data use cases. Understanding the nuances of each framework can help businesses make informed decisions on selecting the right tool to leverage the full potential of their Big Data analytics and processing requirements.
Overview of Apache Flink
Apache Flink is a powerful stream processing framework that excels in real-time data processing and analytics. Flink is designed to handle high-throughput, low-latency processing of data streams with features like stateful computations, event time processing, and fault tolerance. Its architecture allows for dynamic scaling, making it suitable for big data applications where real-time analytics are crucial.
Overview of Apache Spark
Apache Spark is an open-source unified analytics engine known for its speed, ease of use, and advanced analytics capabilities. Spark supports batch processing, interactive queries, and stream processing, which makes it a versatile tool for various big data applications. It includes libraries for SQL, machine learning (MLlib), graph processing (GraphX), and stream processing (Spark Streaming).
Data Processing Models
Stream Processing in Apache Flink
Flink’s stream processing model is distinct, as it treats batch processing as a special case of streaming (known as the unified data processing model). It processes data in real-time, offering robust handling of time and state, allowing for complex event processing.
Batch Processing in Apache Spark
While Spark can handle streaming data through Spark Streaming, it primarily excels in batch processing. Spark operates on RDDs (Resilient Distributed Datasets), which provide fault tolerance and scalability. Data can be processed in micro-batches, which introduces some latency compared to Flink’s real-time processing capabilities.
Performance and Scalability
Performance Comparison
When it comes to processing speed, Flink’s ability to manage event time and state makes it superior for real-time applications. It can process millions of events per second with low latency, making it ideal for use cases that require immediate insights.
Apache Spark, while fast, is generally slower in stream processing compared to Flink due to its micro-batch architecture. However, for batch processing, Spark is significantly faster because it optimizes data processing through DAG (Directed Acyclic Graph) execution planning.
Scalability Considerations
Both Flink and Spark offer horizontal scalability, allowing users to add more nodes to handle larger volumes of data. However, Flink can manage dynamic scaling better in real-time scenarios, providing greater flexibility under variable load conditions.
Ease of Use and Learning Curve
User Experience with Apache Flink
Flink’s API is designed to be user-friendly, especially for developers familiar with Java or Scala. Its DataStream API and DataSet API provide intuitive programming models for building applications.
However, the rich feature set of Flink might pose a learning curve for beginners in big data technologies who are unfamiliar with streaming concepts.
User Experience with Apache Spark
Apache Spark is renowned for its simplicity and ease of use. The Spark SQL module provides a familiar SQL-like interface for querying structured data, making it accessible to data analysts and scientists. Furthermore, the documentation and community support for Spark are extensive, which contributes to a gentler learning curve.
Fault Tolerance and State Management
Fault Tolerance in Apache Flink
Flink has a sophisticated fault tolerance mechanism based on distributed snapshots. It uses a stateful stream processing model where state can be consistently restored after a failure. This guarantees that applications can recover seamlessly without losing any data.
Fault Tolerance in Apache Spark
Spark employs RDDs to achieve fault tolerance by recalculating lost data partitions. Although effective, this may introduce delays during recovery compared to Flink’s snapshotting technique, particularly in environments with high availability requirements.
Use Cases
Best Use Cases for Apache Flink
Flink shines in scenarios that demand real-time analytics and event-driven applications, such as:
- Real-Time Data Processing: Applications requiring immediate insights, such as fraud detection or monitoring systems.
- Event-Driven Applications: Systems that react to streaming events, such as social media monitoring.
- Complex Event Processing: Scenarios where events need to be aggregated or filtered according to complex rules.
Best Use Cases for Apache Spark
Spark is better suited for batch processing and analytics tasks, including:
- Batch Processing: Large datasets, complex analytics jobs that do not require real-time processing.
- Machine Learning: Leveraging MLlib to train models on large datasets.
- Data Warehousing: Running ETL processes on substantial historical datasets.
Community and Ecosystem
Apache Flink Community
Flink has a vibrant community with significant contributions from companies like Alibaba and Netflix. The project is continually evolving, with frequent updates adding new features and enhancements.
Apache Spark Community
With one of the most extensive communities in big data, Spark offers abundant documentation, forums, and support channels. The Apache Software Foundation supports Spark, ensuring consistency and longevity in development and community engagement.
Cost of Implementation
Both Apache Flink and Apache Spark are open-source frameworks with no licensing fees. However, costs can arise from infrastructure, cloud services, and the manpower needed for deployment and maintenance. Choosing between Flink and Spark may depend on the skill set of your team and your specific needs for data processing.
Final Thoughts
Choosing between Apache Flink and Apache Spark largely depends on your specific use case. If your operations require real-time stream processing with low latency, Flink is likely the better option. Conversely, if you need robust batch processing support and a more extensive community backing, Spark would be the appropriate choice. Ultimately, both frameworks have their strengths and cater to diverse big data requirements.
Both Apache Flink and Apache Spark are powerful Big Data processing frameworks, each excelling in different use cases. Apache Flink is better suited for streaming data processing with low latency requirements, while Apache Spark is preferred for batch processing and interactive querying. The choice between the two ultimately depends on the specific requirements of the Big Data application at hand. Both frameworks have their strengths and limitations, and a thorough evaluation based on the project’s needs is recommended to determine the better fit for the given use case.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 How Elasticsearch is Used in Big Data Applications
How Elasticsearch is Used in Big Data Applications
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data