Building a scalable data architecture is crucial for organizations looking to leverage the power of Big Data effectively. In today’s data-driven world, businesses need to manage, analyze, and extract insights from large volumes of data efficiently. A scalable data architecture allows for the seamless handling of growing data volumes, ensuring that systems can expand and adapt to meet evolving business needs. In this article, we will explore key considerations and best practices for building a scalable data architecture that is optimized for Big Data processing.
Understanding Scalable Data Architecture
A scalable data architecture is crucial for organizations that handle large volumes of data. It ensures that the system can grow seamlessly while maintaining performance. A robust architecture is designed to accommodate not only current data demands but also future growth, thereby making it essential for big data initiatives.
Key Components of Scalable Data Architecture
To develop a scalable data architecture, several key components must be included:
- Data Sources: The architecture must account for various data sources, including databases, IoT devices, and online services.
- Data Ingestion: Utilizing frameworks like Apache Kafka or Apache NiFi aids in streaming and batch data ingestion.
- Data Storage: Choosing the right storage solution, such as Hadoop HDFS, Amazon S3, or a NoSQL database, is essential.
- Data Processing: Frameworks such as Apache Spark or Apache Flink facilitate processing large datasets swiftly.
- Data Analytics: Employing BI tools and machine learning frameworks allows for insightful analysis of the data stored.
- Data Governance: Implementing policies and tools for data security, data privacy, and compliance.
Choosing the Right Data Storage Solutions
Selecting the appropriate data storage solutions is pivotal in building a scalable data architecture. Here are some popular options:
1. Distributed File Systems
Distributed file systems like Hadoop Distributed File System (HDFS) are designed to store vast amounts of data across multiple machines, ensuring high availability and fault tolerance.
2. NoSQL Databases
NoSQL databases, such as MongoDB and Cassandra, are preferred for handling unstructured data and providing horizontal scalability. They allow for flexible data models without predefined schemas, which is beneficial for big data applications.
3. Cloud Storage Solutions
With the rise of cloud computing, services like Amazon S3 and Google Cloud Storage offer scalable and cost-effective solutions. They allow businesses to scale up or down based on data requirements without significant hardware investment.
Data Ingestion Strategies
Efficient data ingestion strategies are essential for feeding large volumes of data into the architecture. The ingestion pipeline can be divided into:
1. Batch Processing
Batch processing involves collecting and processing data in scheduled intervals. Tools like Apache Sqoop can help transfer bulk data between relational databases and Hadoop, enabling effective batch ingestion.
2. Stream Processing
For real-time data processing, stream processing frameworks such as Apache Kafka or Apache Pulsar should be utilized. These allow continuous data flow from various sources, making real-time insights actionable.
Integrating Data Processing Frameworks
After ingestion, data must be processed and transformed for analysis. A scalable architecture should integrate one or more data processing frameworks. Consider the following:
1. Apache Spark
Apache Spark is known for its speed and performance. It supports in-memory data processing and can handle both batch and stream data, making it an excellent choice for data-heavy applications.
2. Apache Flink
Apache Flink is perfect for real-time stream processing applications. It offers sophisticated event-time processing capabilities, allowing for complex analytics on streaming data.
3. Data Pipelines
Building a streamlined data pipeline is essential for moving data from ingestion to processing and finally to storage. Tools like Apache Airflow help automate this process, owing to their ease of orchestration for complex workflows.
Data Analytics and Visualization
Once the data has been ingested and processed, the next step is data analytics and visualization. Implementing robust analytics tools enables businesses to derive insights that drive decision-making. Popular solutions include:
1. Business Intelligence Tools
Tools such as Tableau and Microsoft Power BI can visualize large datasets and generate insightful reports, helping stakeholders understand data trends and patterns easily.
2. Machine Learning Frameworks
For more complex analyses, leveraging machine learning frameworks like TensorFlow and scikit-learn can facilitate predictive analytics and advanced data modeling, enhancing data-driven decision-making processes.
Ensuring Data Governance
As data grows, so do compliance and governance challenges. Implementing a robust data governance framework will help manage data integrity, security, and compliance with regulations such as GDPR and CCPA. Considerations include:
- Data Quality: Establishing standards for data accuracy and consistency.
- Data Security: Utilizing encryption and access controls to protect sensitive information.
- Master Data Management (MDM): Facilitating a single, accurate view of key business data.
Scalability Considerations
When designing a scalable architecture, several factors must be considered:
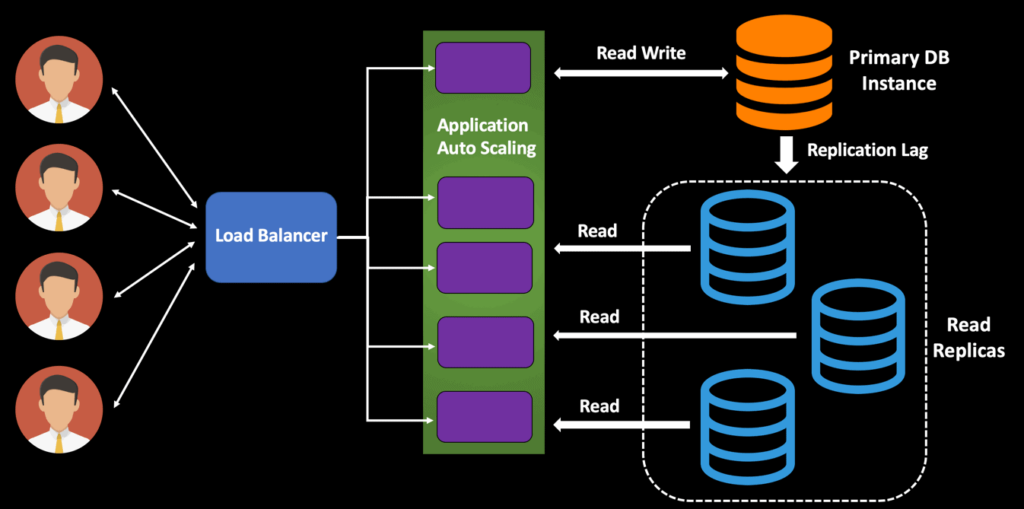
1. Load Balancing
Employing load balancers helps distribute workloads across multiple servers, ensuring no single server becomes a bottleneck, thereby optimizing resource utilization.
2. Elastic Scaling
Cloud services provide the ability to scale resources up or down based on real-time needs, enabling organizations to manage fluctuating workloads efficiently.
3. Microservices Architecture
Adopting a microservices architecture allows individual components of the data processing system to scale independently, making it easier to manage and optimize different parts of the larger architecture.
Monitoring and Maintenance
Continuous monitoring of system performance is vital for maintaining a scalable architecture. Key metrics to monitor include:
- Data Throughput: Measuring the volume of data processed over time to identify potential bottlenecks.
- Latency: Monitoring response time for data processing tasks helps ensure that performance meets business needs.
- Resource Utilization: Keeping tabs on CPU, memory, and storage usage aids in optimizing infrastructure and making necessary adjustments proactively.
Choosing the Right Tools and Technologies
The success of a scalable data architecture hinges on choosing the right tools and technologies. Some recommended tools are:
- Apache Kafka for real-time data streaming.
- Hadoop for distributed data storage and processing.
- Elasticsearch for powerful search capabilities across large data sets.
- DataRobot for automated machine learning.
- Snowflake for cloud-based data warehousing solutions.
Final Thoughts on Building Scalable Data Architecture
Designing a scalable data architecture for big data applications involves careful planning and consideration of various components and technologies. By emphasizing data ingestion, storage, processing, analytics, and governance, organizations can create a robust framework capable of adapting to their evolving data needs. Addressing scalability from the outset ensures long-term sustainability and success in a fast-paced data-driven world.
Building a scalable data architecture in the realm of Big Data involves thoughtful planning, strategic utilization of technologies, and continuous optimization to meet evolving business needs. By following best practices and leveraging the power of tools such as cloud computing, distributed systems, and data orchestration platforms, organizations can establish a robust foundation that allows for seamless growth and adaptation in an increasingly data-driven world.
Related posts:
 The Role of Active Learning in Optimizing Big Data Model Training
The Role of Active Learning in Optimizing Big Data Model Training
 The Impact of Causal Inference on Decision-Making in Big Data
The Impact of Causal Inference on Decision-Making in Big Data
 How to Leverage Swarm Intelligence for Big Data Optimization
How to Leverage Swarm Intelligence for Big Data Optimization
 The Future of Digital Twins in Large-Scale Big Data Simulations
The Future of Digital Twins in Large-Scale Big Data Simulations
 The Role of Causal AI in Understanding Big Data Relationships
The Role of Causal AI in Understanding Big Data Relationships
 How to Perform Large-Scale Time Series Forecasting with Big Data
How to Perform Large-Scale Time Series Forecasting with Big Data
 How to Perform Real-Time Outlier Detection in Big Data Pipelines
How to Perform Real-Time Outlier Detection in Big Data Pipelines
 The Future of AI-Powered Data Wrangling for Big Data Scientists
The Future of AI-Powered Data Wrangling for Big Data Scientists
 The Role of Synthetic Tabular Data Generation in Big Data Training Sets
The Role of Synthetic Tabular Data Generation in Big Data Training Sets
 The Role of AI in Automated Feature Selection for Big Data Models
The Role of AI in Automated Feature Selection for Big Data Models
 The Future of Scalable AI-Driven Big Data Pipelines
The Future of Scalable AI-Driven Big Data Pipelines
 How to Perform Online Data Augmentation for Real-Time AI Applications
How to Perform Online Data Augmentation for Real-Time AI Applications
 How to Optimize Query Execution in Distributed Big Data Systems
How to Optimize Query Execution in Distributed Big Data Systems