Distributed deep learning on big data is a complex yet powerful technique that leverages the capabilities of distributed computing to train deep learning models on massive datasets. With the exponential growth of data generation, traditional deep learning approaches may not be sufficient to handle the scale and complexity of big data. By distributing the training process across multiple nodes or machines, distributed deep learning allows for faster processing, increased scalability, and improved model accuracy. In this article, we will explore the principles, challenges, and best practices of performing distributed deep learning on big data, highlighting the key considerations for maximizing the potential of this cutting-edge technology in the realm of big data analytics.
In today’s technological landscape, big data is becoming an increasingly crucial asset for organizations looking to derive insights and drive strategic decisions. Distributed deep learning is a method that enables practitioners to manage and analyze massive datasets effectively. This article outlines the steps, considerations, and tools necessary to perform distributed deep learning on big data.
Understanding Distributed Deep Learning
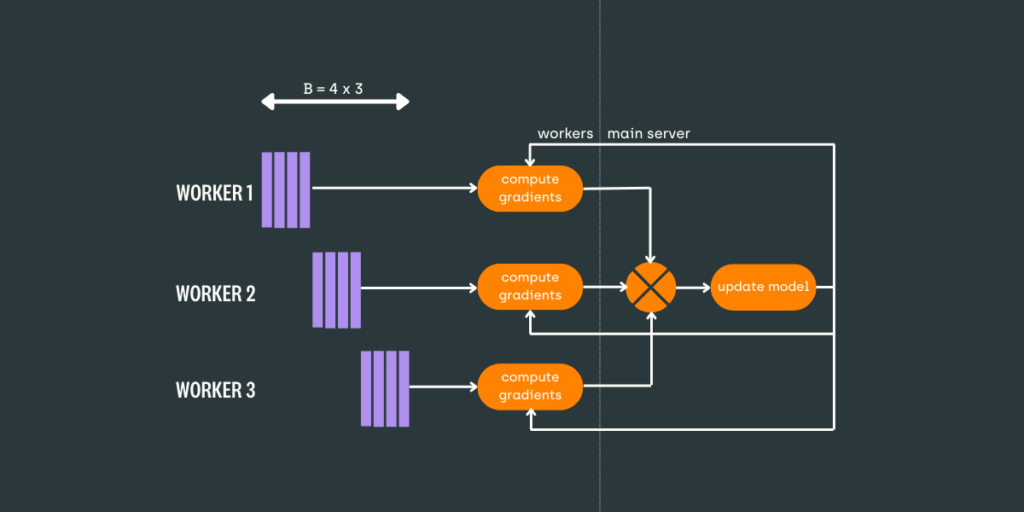
Distributed deep learning refers to the technique of executing deep learning tasks across multiple computing resources. By distributing the workload, data scientists can leverage the collective power of various processors, facilitating faster training and better utilization of data. With the ever-growing volume of data that organizations deal with, distributed learning has become essential for deep learning models to remain effective.
Key Benefits of Distributed Deep Learning
- Scalability: Distributed deep learning allows organizations to scale their learning processes dynamically with data requirements.
- Efficiency: It significantly decreases the training time for deep learning models, enabling quicker iterations and deployments.
- Resource Utilization: This process enhances resource utilization by distributing workloads across various hardware resources and nodes.
Prerequisites for Distributed Deep Learning
Before diving into distributed deep learning, it’s essential to set up the following:
- Hardware Infrastructure: Ensure you have sufficient GPU/CPU resources, memory, and storage to handle large datasets.
- Data Storage Solutions: Use cloud platforms or distributed file systems like HDFS or Amazon S3 for efficient data storage and access.
- Frameworks and Libraries: Familiarize yourself with deep learning frameworks that support distributed training, such as TensorFlow, PyTorch, and Apache MXNet.
Setting Up Your Environment
To establish an environment conducive for distributed deep learning, follow these steps:
1. Choose a Distributed Framework
Several frameworks are specifically designed for distributed deep learning:
- TensorFlow: With its built-in support for distributed training, TensorFlow offers TensorFlow Distributed (TF Distributed) which helps in spreading the model training task across multiple devices.
- PyTorch: PyTorch’s DistributedDataParallel allows you to easily set up distributed training with minimal adjustments to your code.
- Apache MXNet: Known for its scalability, MXNet allows for efficient training across multiple GPUs and can handle huge datasets effectively.
2. Install Necessary Libraries
Install the necessary libraries and tools using package managers. For instance:
pip install tensorflow torch torchvisionEnsure you are also utilizing libraries that facilitate big data processing like Apache Spark, which integrates well with deep learning frameworks.
3. Configure Your Cluster
Set up a computing cluster that includes multiple nodes. Each node should have identical libraries and configurations for consistent execution. Consider tools like Kubernetes for container orchestration or Apache Mesos for cluster management.
Data Preprocessing for Distributed Deep Learning
Data preprocessing is vital in deep learning, particularly with large datasets. Here’s how to optimize your data preprocessing steps:
1. Data Cleaning
Eliminate duplicates, handle missing values, and correct inconsistencies in your dataset to ensure quality data for model training.
2. Data Transformation
Utilize techniques such as normalization and standardization to improve the performance of your deep learning models.
3. Data Sharding
Divide your dataset into smaller, manageable chunks or *shards*, enabling each node to work with a subset of the data, thus reducing the overall training load on each node.
Implementing Distributed Training
With the environment ready and data prepared, follow these steps to implement distributed training:
1. Define Your Model
Create a deep learning model using your chosen framework. Here is an example in TensorFlow:
import tensorflow as tf
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(input_shape,)),
tf.keras.layers.Dense(10, activation='softmax')
])
return model2. Use Distributed Strategy
For TensorFlow, utilize the tf.distribute.Strategy to set up distribution. This strategy allows you to define how the model should be distributed across devices.
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = create_model()
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])3. Train the Model
Train your model using the fit() method, taking care to leverage the distributed strategy.
model.fit(dataset, epochs=10)Monitoring and Optimizing Distributed Training
After implementing distributed training, it’s crucial to monitor the performance and make necessary adjustments:
1. Use Monitoring Tools
Utilize tools like TensorBoard or MLflow to visualize training metrics, inspect logs, and debug problems throughout the training process.
2. Performance Tuning
Experiment with batch sizes, learning rates, and optimization algorithms. Additionally, keep an eye on resource utilization and adjust your cluster configurations accordingly.
3. Gradient Accumulation
If resources are limited, consider applying gradient accumulation strategies to effectively simulate larger batch sizes while using fewer resources.
Evaluating and Testing the Model
Upon completion of the training phase, evaluating the model is crucial:
1. Validation Data
Split your initial dataset into training, validation, and testing sets to ensure your model generalizes well to unseen data.
2. Model Evaluation Metrics
Select appropriate metrics such as accuracy, precision, recall, and F1-score to validate the model’s performance based on your specific use case.
test_loss, test_accuracy = model.evaluate(test_dataset)
print('Test accuracy:', test_accuracy)3. Deploying the Model
Once satisfied with the model’s performance, deploy it in a cloud-based or on-premises solution to enable real-time predictions.
Challenges in Distributed Deep Learning
While distributed deep learning offers numerous advantages, it does come with challenges that practitioners should be aware of:
1. Communication Overhead
As models scale across multiple nodes, communication overhead can become a bottleneck. Techniques like gradient compression can mitigate these challenges.
2. Fault Tolerance
Failures during training can lead to data loss or inconsistencies. Implementing checkpoints and recovery mechanisms is essential to safeguard against unexpected failures.
3. Resource Management
Managing and optimizing resource usage efficiently remains one of the critical challenges in a distributed environment.
Conclusion
Distributed deep learning provides an effective solution for handling big data, offering scalability and efficiency for training deep learning models. By following these guidelines, organizations can harness the power of distributed computing and machine learning to innovate and thrive in the data-driven era.
Performing distributed deep learning on big data is a vital strategy in harnessing the power of large datasets for machine learning applications. By leveraging distributed computing frameworks and advanced algorithms, organizations can efficiently process and analyze massive volumes of data to extract valuable insights and drive innovation in the era of big data analytics. This approach not only enables enhanced model training and improved scalability but also plays a key role in accelerating the development of cutting-edge technologies and solutions in the field of big data.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data