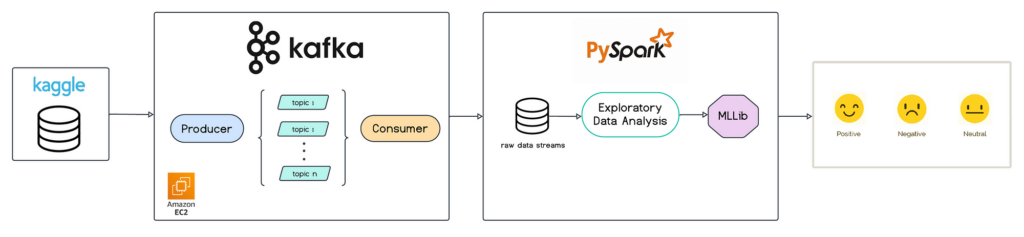
Performing Large-Scale Sentiment Analysis with Apache Kafka is a powerful tool in the realm of Big Data analytics. By harnessing the capabilities of Apache Kafka, businesses can efficiently process massive amounts of data to gain valuable insights into customer sentiment. This allows organizations to gather, analyze, and act upon real-time feedback from various sources such as social media, customer reviews, and surveys. In this article, we will explore how Apache Kafka enables large-scale sentiment analysis and the benefits it offers in the realm of Big Data analytics.
In today’s digital age, the ability to analyze sentiments from vast data streams has become crucial for businesses looking to understand customer opinions and trends. Apache Kafka is a powerful open-source distributed event streaming platform designed to handle real-time data feeds exceptionally well. This article explores how to leverage Apache Kafka for large-scale sentiment analysis, detailing essential components, tools, and implementation strategies.
What is Sentiment Analysis?
Sentiment analysis is a technique used to determine the emotional tone behind a body of text. This can involve categorizing sentiments as positive, negative, or neutral. With the explosion of social media and online reviews, the need for effective sentiment analysis techniques has skyrocketed.
Why Use Apache Kafka for Sentiment Analysis?
When processing large-scale data, traditional batch processing systems often fall short due to volume, velocity, and variety challenges. Apache Kafka stands out for several reasons:
- High Throughput: Kafka can handle thousands of messages per second, making it suitable for real-time analytics.
- Scalability: Kafka can easily scale horizontally, adding more nodes to handle increasing data loads.
- Durability and Fault Tolerance: Kafka allows data replication across nodes, ensuring no data is lost even in hardware failures.
- Integration: Kafka integrates seamlessly with data processing frameworks like Apache Spark, Apache Flink, and machine learning libraries.
Key Components of Apache Kafka
To perform sentiment analysis effectively, you need to understand the fundamental components of Apache Kafka:
- Producers: Producers are applications that publish messages to Kafka topics.
- Topics: A topic is a category or feed name to which records are published.
- Consumers: Consumers are applications that subscribe to topics and process the feed of published messages.
- Brokers: Brokers are Kafka servers that store the data and serve client requests.
- ZooKeeper: ZooKeeper manages and coordinates Kafka brokers.
Setting Up Your Apache Kafka Environment
Before diving into sentiment analysis, setting up your Apache Kafka environment is essential. Here’s a step-by-step guide:
1. Install Apache Kafka
You can download Kafka from the official Apache Kafka website. Follow the instructions for your operating system, and ensure you have Java installed on your machine.
2. Start ZooKeeper
Kafka relies on ZooKeeper. You can start it with the following command:
bin/zookeeper-server-start.sh config/zookeeper.properties3. Start Kafka Server
Once ZooKeeper is running, start up the Kafka server:
bin/kafka-server-start.sh config/server.properties4. Create a Kafka Topic
To perform sentiment analysis, create a topic that will hold incoming social media feeds or reviews:
bin/kafka-topics.sh --create --topic sentiment-data --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1Data Ingestion into Kafka
After setting up Kafka, data ingestion is the next critical step. You can ingest data from various sources such as social media platforms, web scrapers, or APIs. Using Kafka producers, you can send data to your topic:
Using Kafka Producer API
Implement a Kafka producer using programming languages such as Java, Python, or Scala. Here’s how to do it in Python using the `kafka-python` library:
from kafka import KafkaProducer
import json
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
# Sample data
data = {'text': 'I love using Kafka for real-time processing!', 'sentiment': 'positive'}
producer.send('sentiment-data', value=data)
producer.flush()Processing Data with Apache Spark
To analyze the streamed data from Kafka, you can use Apache Spark with its Spark Streaming module. This allows real-time processing and analysis. Here’s an overview of how to set it up:
1. Set Up Spark Streaming
Install Apache Spark and integrate it with Kafka. Ensure you add the necessary dependencies in your build file. For instance, if you’re using Maven, your `pom.xml` should include:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-Kafka-0-10_2.12</artifactId>
<version>3.3.0</version>
</dependency>2. Creating a Spark Streaming Application
Here’s a simple Spark Streaming application that reads from the Kafka topic and processes it:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import StringType
spark = SparkSession.builder
.appName("Kafka Sentiment Analysis")
.getOrCreate()
# Read data from Kafka
df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "sentiment-data")
.load()
# Define schema
schema = "text STRING, sentiment STRING"
result = df.selectExpr("CAST(value AS STRING) AS json")
.select(from_json(col("json"), schema).alias("data"))
.select("data.*")
# Start the streaming query
query = result.writeStream
.outputMode("append")
.format("console")
.start()
query.awaitTermination()Implementing Sentiment Analysis
Once you have the streaming data ready, the next step is implementing sentiment analysis. You can use various machine learning libraries like NLTK, spaCy, or TensorFlow to classify sentiments. Below is a simplified version using NLTK:
1. Install NLTK
First, ensure NLTK is installed:
pip install nltk2. Perform Sentiment Analysis
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
# Create SentimentIntensityAnalyzer object
sia = SentimentIntensityAnalyzer()
# Function to analyze sentiment
def get_sentiment(text):
score = sia.polarity_scores(text)
return 'positive' if score['compound'] > 0.05 else 'negative' if score['compound'] < -0.05 else 'neutral'
# Example usage
print(get_sentiment("I love using Kafka for real-time processing!")) # Output: positiveStoring Results for Further Analysis
After processing the sentiment analysis, it’s crucial to store the results for further analysis and reporting. You can use databases like MongoDB, Cassandra, or traditional relational databases for storage.
Storing in MongoDB
To store results into MongoDB, ensure you install the required library:
pip install pymongofrom pymongo import MongoClient
client = MongoClient("mongodb://localhost:27017/")
db = client["sentiment_analysis"]
collection = db["results"]
# Example data
result_data = {'text': 'I love using Kafka for real-time processing!', 'sentiment': 'positive'}
collection.insert_one(result_data)Visualizing Sentiment Analysis Results
Visualization is essential to understanding your analysis. Tools like Tableau, Grafana, or libraries like Matplotlib and Seaborn in Python can help visualize sentiment trends over time.
Visualizing with Matplotlib
import matplotlib.pyplot as plt
# Sample data
sentiment_counts = {'positive': 15, 'negative': 5, 'neutral': 10}
plt.bar(sentiment_counts.keys(), sentiment_counts.values())
plt.xlabel('Sentiment')
plt.ylabel('Count')
plt.title('Sentiment Analysis Results')
plt.show()Implementing a large-scale sentiment analysis system using Apache Kafka allows organizations to effectively gauge public sentiment in real-time. With its high throughput, scalability, and integration capabilities, Kafka proves to be a robust solution for handling the complexities of big data analytics.
Leveraging Apache Kafka for large-scale sentiment analysis offers significant advantages in handling vast amounts of data efficiently and in real-time. By incorporating Kafka's capabilities for data streaming, scalability, and fault tolerance, organizations can effectively process and analyze sentiment data at scale within their Big Data infrastructure. This approach enables actionable insights to be derived quickly, enhancing decision-making processes and driving business growth.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI