In today’s data-driven world, organizations are increasingly relying on big data to make strategic decisions and gain valuable insights. For big data teams, having a robust data science platform is crucial to effectively manage and analyze large volumes of data. Building a data science platform tailored for big data tasks requires careful planning and implementation. In this guide, we will explore key considerations and best practices for building a data science platform that enables big data teams to drive innovation and make data-driven decisions effectively.
Understanding the Importance of a Data Science Platform
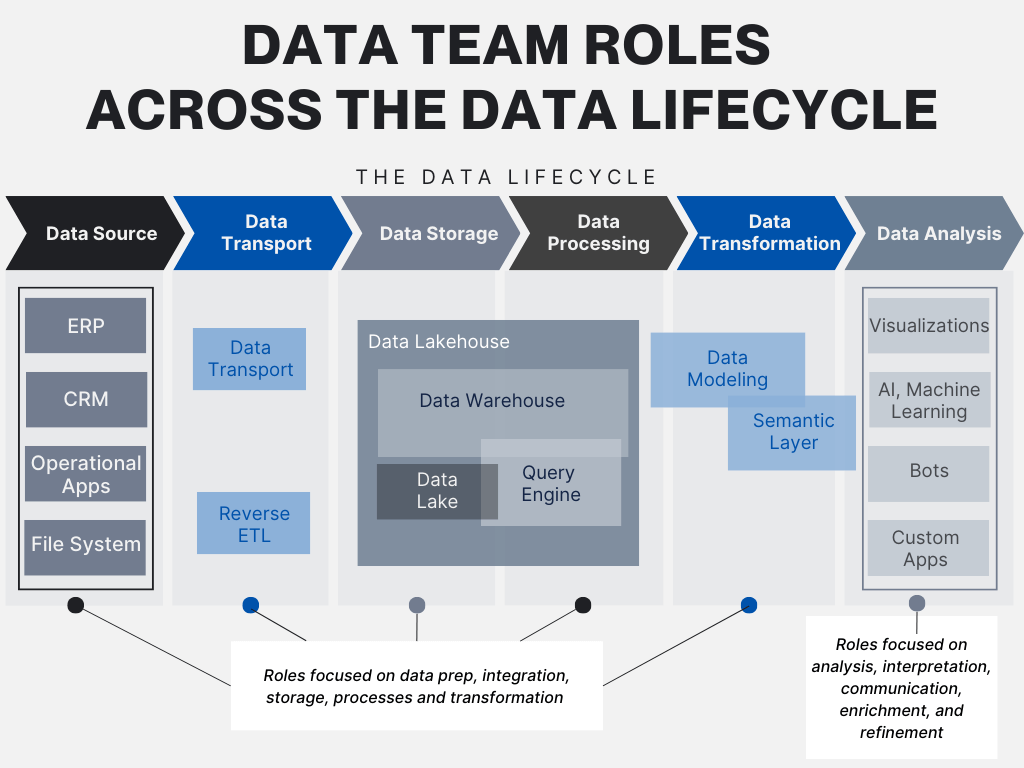
A data science platform acts as a collaborative environment that empowers Big Data teams to efficiently analyze vast datasets, derive insights, and deploy machine learning models. Building a robust data science platform is critical because it enables scalability, enhances productivity, and ensures data governance. A well-structured platform facilitates collaboration between data engineers, data scientists, and business analysts, ultimately leading to better decision-making processes.
Components of a Data Science Platform
Creating an effective data science platform involves several core components:
- Data Ingestion: This range of activities involves acquiring and storing data from diverse sources. Establishing a reliable pipeline for data ingestion is crucial for ensuring that data is readily available for analysis.
- Data Storage: Choosing the right data storage solution is vital. Options include traditional relational databases, NoSQL databases, and cloud-based storage systems. Each of these has its benefits depending on your specific use cases.
- Data Processing: Implementing frameworks such as Apache Spark, Hadoop, or Flink enables efficient processing of large datasets either in batch or real-time.
- Data Analysis: Leveraging tools like Jupyter Notebooks, Apache Zeppelin, or tools like RStudio allows data scientists to conduct extensive data analyses and visualize the results.
- Machine Learning Operations (MLOps): Integrating MLOps tools facilitates smooth deployment and monitoring of machine learning models. Tools includes Kubeflow, MLflow, and TFX.
Step-by-Step Guide to Building a Data Science Platform
Step 1: Define Requirements
Before constructing your data science platform, it’s imperative to clearly understand the requirements of your Big Data teams. Engage with your stakeholders—including data scientists, analysts, and engineers—to outline the following:
- Types of data to be processed
- Expected workloads and processing requirements
- Security and compliance needs
- Integration with existing tools and workflows
Step 2: Choose Your Infrastructure
Your infrastructure choice is a foundational aspect of your data science platform. You have several options:
- On-Premises: A traditional data center setup offers control and security but can be costly and less flexible.
- Cloud-Based Solutions: Platforms like AWS, Google Cloud, or Azure provide managed services that are scalable and flexible, reducing the overhead of infrastructure management.
- Hybrid Solutions: Combining both on-premises and cloud solutions might be advantageous if you have specific compliance or performance needs.
Step 3: Implement Data Ingestion Pipelines
Once you have defined your requirements and set up infrastructure, the next step is to implement data ingestion pipelines. This is a crucial part of your data science platform as it determines how efficiently data is moved into the system. Common tools for data ingestion include:
- Apache NiFi: Excellent for data flow automation between systems.
- Apache Kafka: Great for real-time data processing.
- Talend: Good for ETL (Extract, Transform, Load) operations.
Ensure that your chosen method supports both batch processing and real-time streaming to accommodate diverse data workflows.
Step 4: Select Appropriate Data Storage Solutions
Your data storage solution must suit the analyzed data’s structure, volume, and velocity. Choices include:
- SQL Databases: Ideal for structured data and complex queries.
- NoSQL Databases: Suitable for unstructured or semi-structured data, providing scalability and flexibility.
- Data Lakes: Storing raw data in its original format allows for schema-on-read, making it versatile for diverse analyses.
Carefully analyze the anticipated data workloads to ensure optimal performance from your selected storage solution.
Step 5: Enable Effective Data Processing
To process large datasets effectively, implement a distributed data processing framework. Apache Spark is a popular choice due to its ability to handle both batch and stream processing efficiently. Considerations include:
- Choosing between local mode or a cluster mode for distributed computing.
- Planning for resource allocation to optimize performance and reduce costs.
- Building data processing workflows that incorporate ETL processes to prepare data for analysis.
Step 6: Integrate Data Analysis Tools
Your data science platform must provide tools for data analysis and visualization. Essential components include:
- Integrated Development Environments (IDEs): Jupyter Notebooks and RStudio are essential for interactive data analysis.
- Visualization Tools: Libraries such as Matplotlib, Seaborn, and platforms like Tableau can be integrated to provide interactive visualizations.
- Data Collaboration Tools: Platforms supporting collaboration, such as Git, become vital for version control and collaborative coding.
Step 7: Implement MLOps Framework
To operationalize machine learning, it’s crucial to establish an MLOps framework. This will help automate the lifecycle of your machine learning models. Recommendations include:
- Model Deployment: Implement tools like Kubernetes for managing the deployment of ML models.
- Monitoring and Maintenance: Use libraries and tools like Prometheus for tracking model performance and data drift.
- Collaborative Model Development: Encourage data science teams to use version control like DVC for managing datasets and models.
Step 8: Ensure Robust Security and Compliance
Data security and compliance with regulations (such as GDPR or HIPAA) should be woven into your data science platform from the ground up. Key steps include:
- Implementing data encryption both at rest and in transit.
- Setting strict access controls to limit who can view sensitive information.
- Regularly auditing your platform to ensure compliance and security practices are being followed.
Step 9: Foster a Culture of Collaboration
For a data science platform to be effective, the culture surrounding it matters. Encourage collaboration among data scientists, data engineers, and business stakeholders. Consider the following:
- Establishing cross-functional teams to work on data initiatives.
- Providing training and workshops to upskill team members on platform usage and data literacy.
- Facilitating regular meetings and feedback sessions to ensure alignment and address pain points.
Step 10: Continuously Iterate and Improve
The landscape of Big Data is constantly evolving, and so should your data science platform. Adopt an agile approach to continuously iterate and improve the following aspects:
- Performance of data ingestion and processing pipelines
- Integration of new tools and technologies
- Feedback from users to make necessary adjustments
Regularly evaluating the performance and effectiveness of your platform will ensure it meets the demands of your data teams and optimizes productivity.
Building a robust data science platform for Big Data teams is crucial for optimizing data processing, analysis, and decision-making. By implementing scalable infrastructure, integrating advanced analytics tools, and fostering collaboration among team members, organizations can unleash the full potential of their data resources. This allows for informed insights, innovation, and competitive advantage in the rapidly evolving landscape of Big Data.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works
 The Impact of Big Data on Financial Services and Banking
The Impact of Big Data on Financial Services and Banking
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges