Self-supervised learning has emerged as a powerful technique in the realm of Big Data AI models, offering notable advantages in training data-hungry algorithms efficiently. In the context of Big Data, where vast amounts of unlabeled data are commonplace, self-supervised learning provides a promising avenue for leveraging this abundance to enhance the performance of AI models. This approach enables systems to learn representations from the data itself, without the need for explicit labels, thereby paving the way for more robust and scalable solutions in the era of Big Data analytics. In this article, we delve into the pivotal role that self-supervised learning plays in driving innovation and unlocking the full potential of AI models in the realm of Big Data.
Self-supervised learning (SSL) has become a transformative technique in the field of artificial intelligence (AI), particularly as it relates to Big Data. This innovative learning paradigm is both efficient and effective, filling gaps left by traditional supervised and unsupervised learning methods. By leveraging vast amounts of unlabeled data, SSL enables AI models to learn and derive intricate patterns that were previously challenging to identify.
Understanding Self-Supervised Learning
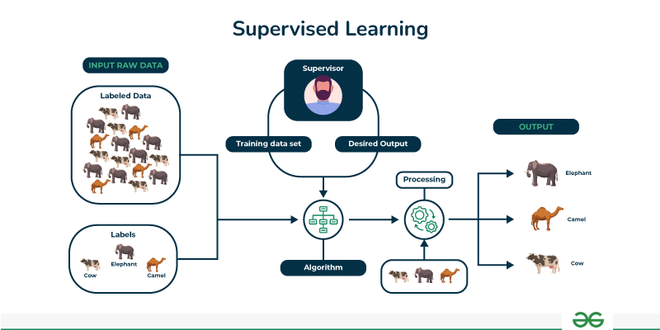
Self-supervised learning is characterized by its ability to create supervisory signals from the data itself. Unlike supervised learning, which relies on labeled datasets, SSL algorithms generate labels from the input data to facilitate training. For instance, in image processing, a model may learn to predict missing parts of an image or the sequence of frames in a video.
Through this mechanism, SSL not only maximizes available data but also minimizes the dependency on extensive human labeling. By effectively utilizing unlabeled data, SS models can expose themselves to broader data distributions. This is particularly valuable in the context of Big Data, where the sheer volume and diversity of data can be overwhelming.
The Importance of SSL in Big Data Contexts
In Big Data scenarios, the amount of data generated can be staggering, often making traditional supervised learning techniques inefficient. Self-supervised learning addresses several challenges posed by Big Data:
1. Data Scarcity and Labeling Cost
Labeling data for supervised learning can be extremely time-consuming and expensive. In many sectors, obtaining expert annotations is not feasible, leading to potential bottlenecks in training models. Self-supervised learning alleviates this issue by creating label-like feedback from unstructured data directly, making it cost-effective and quicker to train AI models without compromising on data quality.
2. Harnessing the Power of Unlabeled Data
The vast majority of data generated today remains unlabeled; however, it still holds valuable insights. SSL thrives in such environments by identifying and using these insights effectively. For instance, in fields like healthcare, sensor data, or social media posts, valuable relationships and patterns can be discovered through self-supervised techniques, enhancing model performance.
3. Robustness and Generalization
Models trained using SSL often exhibit stronger generalization capabilities. By learning from numerous diverse examples within unlabeled data, these models acquire a more nuanced understanding of various contexts, leading to enhanced performance across different tasks. This is especially beneficial in Big Data applications, where the diversity of input data can lead to variations in model accuracy.
Applications of Self-Supervised Learning in Big Data AI Models
The applications of self-supervised learning span multiple industries, showcasing its versatility within Big Data frameworks:
1. Natural Language Processing (NLP)
In the realm of NLP, SSL has been particularly impactful. Techniques such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) utilize self-supervised objectives to learn language representations from vast corpuses of text. By predicting masked words in sentences, these models achieve remarkable performance in various downstream tasks such as sentiment analysis and language translation.
2. Computer Vision
In computer vision, models like SimCLR and MoCo (Momentum Contrast) have demonstrated the effectiveness of SSL. By using contrastive learning, these models can differentiate between similar and different images, enhancing tasks like object detection and image classification. As images are a predominant form of data in Big Data, leveraging SSL improves accuracy while reducing required annotated datasets.
3. Reinforcement Learning
Self-supervised learning can also play a significant role in reinforcement learning scenarios, where agents learn from interactions with their environment. SSL techniques can generate self-supervised rewards by simulating various scenarios, allowing agents to improve their decision-making processes without exhaustive manual feedback.
Challenges and Limitations of Self-Supervised Learning
While the benefits of self-supervised learning in the context of Big Data are undeniable, there are challenges and limitations to consider:
1. Complexity of Implementation
Implementing SSL can be more complex than traditional supervised methods. The need for designing appropriate self-supervised tasks that align well with the dataset can require advanced expertise and experimentation.
2. Overfitting to Unstructured Data
There’s a risk that models may tune themselves too specifically to the peculiarities of unstructured data, leading to overfitting. This necessitates careful consideration of the training set and potentially additional validation to ensure robustness.
3. Interpretability Issues
The convolution of data derived labels and learned representations may lead to reduced model interpretability. In domains where model explainability is crucial, such as healthcare or finance, this can pose significant challenges.
Future Directions for Self-Supervised Learning in Big Data
The future of self-supervised learning in Big Data AI models looks promising as researchers continue to explore and push the boundaries of this technique:
1. Advanced Architectures
Innovations in architectures, particularly transformer models and generative adversarial networks (GANs), signal a new era for SSL. Future architectures may be able to better leverage the complexities of Big Data, enhancing efficiency and effectiveness.
2. Hybrid Learning Models
Combining self-supervised learning with traditional supervised and unsupervised learning approaches could yield powerful hybrid models. These models may utilize labeled data for downstream tasks while benefiting from the vast amounts of unlabeled data.
3. Reducing Bias
SSL holds potential for reducing bias in AI models by allowing them to learn diverse patterns from extensive data. As awareness surrounding ethical AI continues to rise, this aspect of SSL may see increased research and application.
Conclusion
The evolution of self-supervised learning is undeniably reshaping the landscape of AI applications in Big Data. Its ability to leverage unlabeled data, ease the burden of human labeling, and enhance the robustness and generalization of models are just a few of the benefits that make it a crucial area of focus for future AI development. As advancements continue, SSL is likely to play an even more pivotal role in ensuring that AI can respond to the challenges set forth by the vast and complex world of Big Data.
Self-supervised learning plays a crucial role in enhancing Big Data AI models by enabling them to learn from unlabeled data, thereby improving their accuracy and efficiency in handling large and complex datasets. Embracing self-supervised learning techniques can significantly enhance the capabilities of AI models in the realm of Big Data analytics, paving the way for more advanced and effective data-driven solutions.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem