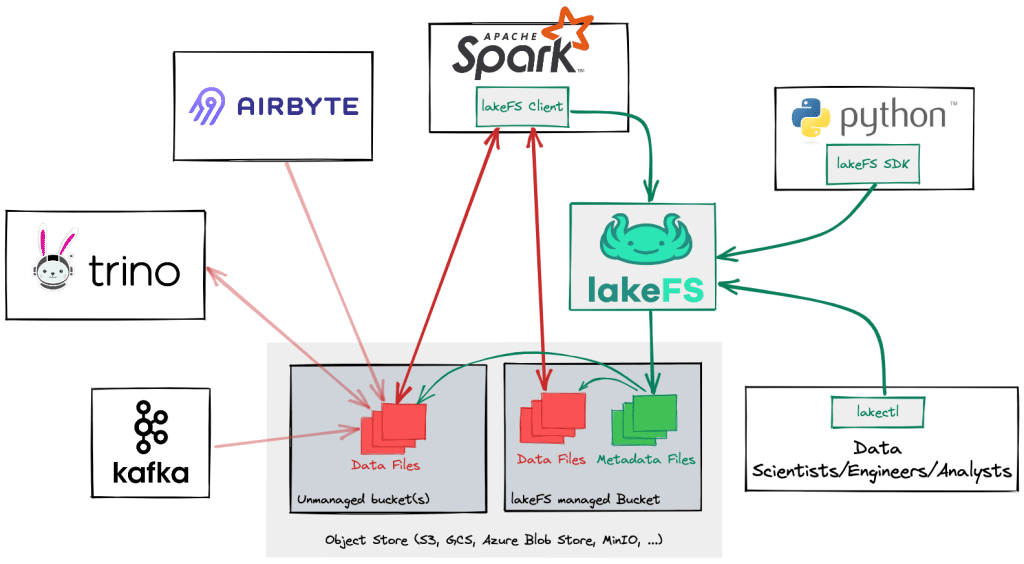
LakeFS is a powerful tool that brings the benefits of version control to Big Data pipelines. By using LakeFS, data engineers and analysts can easily manage and track changes to large datasets, ensuring data integrity and consistency throughout the pipeline workflow. This innovative solution allows for efficient collaboration, reproducibility, and auditability in handling vast amounts of data. In this article, we will explore how to leverage LakeFS for version control in Big Data pipelines, highlighting its key features and benefits for organizations working with Big Data.
In the world of Big Data, managing vast datasets effectively is crucial. As organizations collect and process enormous volumes of information, maintaining data integrity and facilitating seamless collaboration among various teams becomes imperative. This is where LakeFS comes into play as a powerful tool for version control in Big Data pipelines.
What is LakeFS?
LakeFS is an open-source data versioning solution designed explicitly for data lakes. By extending the capabilities of data lakes with features akin to traditional version control systems like Git, LakeFS allows data teams to track changes, manage dataset versions, and collaborate more efficiently. It transforms the way data engineers and data scientists interact with their data, making it just as easy to work with as code.
Benefits of Using LakeFS
Implementing LakeFS in your Big Data infrastructure brings several advantages:
- Version Control: Maintain accurate versions of datasets, enabling easy rollback to previous states.
- Collaboration: Allow multiple teams to work on the same datasets without overwriting each other’s changes.
- Data Integrity: Ensure the reliability of data by tracking alterations and having a clear audit trail.
- Branching & Merging: Similar to Git, LakeFS supports branching, allowing you to create experimental features with ease.
- Scalability: Efficiently manage large datasets without compromising on performance.
Getting Started with LakeFS
Installation
To start using LakeFS, you need to install it in your environment. You can set it up locally or deploy it in the cloud. Below are the key steps for a local installation:
git clone https://github.com/treeverse/lakeFS.git
cd lakeFS
make build
./bin/lakefs serveFor production deployment, consider using a Docker image or a cloud-native setup based on your organization’s requirements.
Connecting LakeFS with Your Data Lake
Once LakeFS is installed, you need to connect it with your existing data lake storage, such as Amazon S3 or Google Cloud Storage. Here are the steps:
- Log in to LakeFS using the admin console.
- Configure the storage backend by providing the necessary credentials and connection settings.
- Once configured, verify the connection by browsing the datasets available in LakeFS.
Using LakeFS for Data Version Control
Creating a Repository
To start versioning your datasets in LakeFS, you need to create a repository. Think of it as a location within LakeFS where your data lives:
lakefs init my-data-repoThis command initializes a new repository named my-data-repo. You can later push datasets into this repository.
Uploading Datasets
Once you have a repository set up, you can upload datasets easily:
lakefs upload my-data-repo s3://my-bucket/dataset.csvThis command uploads the dataset to the specified location in your cloud storage. After uploading, you can begin tracking versions.
Branching and Merging
One of LakeFS’s compelling features is its support for branching, enabling you to create separate areas for experimentation:
lakefs branch create my-branchThis command creates a branch named my-branch in your repository. You can now make changes in this environment without affecting the main dataset.
To merge these changes afterward, use:
lakefs merge my-branch mainThis command merges the branch back into the main dataset, keeping track of all changes made during the process.
Working with Data Versions
Versioning Datasets
LakeFS automatically tracks versions of datasets every time you upload or modify them. You can inspect the versions available in your repository using:
lakefs versions my-data-repoThis command lists all versions of the datasets in the my-data-repo repository, allowing you to pinpoint any previous state for rollback purposes.
Rollback Operations
Should you encounter issues or need to revert to a previous dataset version, LakeFS makes rollback operations simple:
lakefs checkout my-data-repo commit_idReplace commit_id with the ID of the specific version you wish to revert to. This command restores the dataset to that state, ensuring business continuity.
Data Lakes and Governance
Effective governance of data is essential for organizations to comply with regulations and industry standards. LakeFS contributes to data governance in several ways:
- Audit Trails: Every change in the dataset is tracked, providing a clear audit trail for compliance.
- Access Controls: Manage user permissions effectively to restrict access to sensitive data.
- Data Quality: Maintain high data quality by allowing data teams to verify changes and revert if necessary.
Integrating LakeFS with Other Tools
LakeFS seamlessly integrates with numerous tools commonly used in the Big Data ecosystem:
Apache Spark
Integrating LakeFS with Apache Spark allows data engineers to leverage Spark’s capabilities while benefiting from LakeFS’s version control:
spark.read.format("lakefs").load("my-data-repo/path/to/table")Airflow
When integrating with Apache Airflow, you can orchestrate your data pipelines while taking advantage of LakeFS’s versioning to ensure reliable data processing workflows.
Real-World Use Cases of LakeFS
Several organizations have successfully implemented LakeFS to improve their data management processes:
- Finance Sector: Financial institutions are using LakeFS to ensure data integrity during model training and testing phases.
- Healthcare: Healthcare providers leverage LakeFS to maintain accurate records while complying with regulations.
- E-commerce: E-commerce platforms use LakeFS to manage datasets for recommendation systems and inventory tracking.
Conclusion: Transforming Your Big Data Management with LakeFS
LakeFS is revolutionizing the way organizations manage their Big Data pipelines. By enabling version control, facilitating seamless collaboration, and ensuring governance, it empowers data teams across industries. Whether you are in finance, healthcare, or e-commerce, implementing LakeFS can contribute significantly to your data management strategy.
By utilizing LakeFS effectively, organizations can not only enhance their operational efficiency but also drive innovation through improved data-driven decision-making.
LakeFS offers a reliable solution for version controlling data lakes in Big Data pipelines, enabling teams to efficiently manage data changes, collaborate seamlessly, and ensure data integrity in a scalable and flexible manner. By implementing LakeFS, organizations can streamline their Big Data processes and enhance overall data quality and reliability.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works
 The Impact of Big Data on Financial Services and Banking
The Impact of Big Data on Financial Services and Banking