In the realm of Big Data analytics, optimizing query performance is paramount to ensuring efficient data processing and analysis. One powerful approach to speeding up analytical queries is through vectorized query execution. By leveraging vectorization, data processing can be done in a more streamlined and efficient manner, resulting in faster query execution times and improved overall performance. In this article, we will explore how to harness the benefits of vectorized query execution for faster Big Data analytics, discussing its advantages and providing practical tips for implementation.
As the demand for faster processing and analysis of large datasets grows, vectorized query execution has emerged as a game-changing technique in the realm of Big Data analytics. This article will explore the fundamentals, advantages, and implementation strategies of vectorized execution in modern data analytics frameworks.
What is Vectorized Query Execution?
At its core, vectorized query execution refers to the technique of executing database operations on batches of data, known as vectors, rather than processing records individually. This method optimizes both memory access and CPU usage, significantly speeding up data processing tasks.
Benefits of Vectorized Query Execution
Vectorized execution provides numerous advantages over traditional row-wise processing, including:
- Improved Performance: By processing data in vectors or columns, systems leverage modern CPU architectures more effectively, leading to faster execution times.
- Reduced Memory Access: Accessing memory in contiguous blocks minimizes cache misses, making data retrieval more efficient.
- Better CPU Utilization: Vectorized operations can take full advantage of SIMD (Single Instruction, Multiple Data) capabilities of modern processors, allowing for parallel execution of the same instruction across multiple data points.
- Enhanced Data Compression: Vectorized processing effectively utilizes data at the column level, improving the performance of columnar databases, which are optimized for analytical queries.
Understanding Vectorized Execution in Action
To grasp how vectorized execution works, consider the following basic example. Instead of processing each row of a database separately, vectorized execution allows you to collect multiple rows (or even multiple columns) of data together and operate over them:
Row-based:
For each row in the table:
execute some operation
Vectorized:
For every vector of rows:
execute the operation on the entire vector
This paradigm shift significantly boosts query performance, especially for analytical queries that process large amounts of data at once.
Implementing Vectorized Query Execution
Many modern Big Data tools and frameworks support vectorized query execution. Here are some prominent ones:
Apache Arrow
Apache Arrow is an open-source project designed to bridge the gap between various data analytics systems through a shared, in-memory columnar format. By using Arrow, you can efficiently transfer data between different processing engines while leveraging vectorized execution capabilities.
Key Features of Apache Arrow:
- Columnar storage and processing for analytical workloads.
- Cross-language support for various programming languages like Python, Java, C++, and R.
- Support for SIMD operations to enhance operational efficiency.
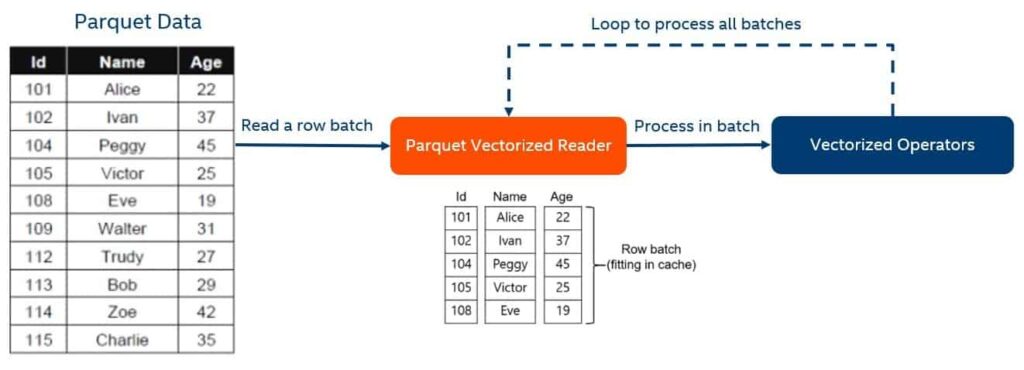
Apache Parquet
Apache Parquet is a columnar storage format that facilitates the efficient handling of complex data structures. Using Parquet with Apache Spark or Hive can optimize query performance significantly by taking advantage of vectorized execution.
Using Parquet with Spark:
spark.read.parquet("path/to/data")
.select("column1", "column2")
.filter("column1 > 1000")
.show()
By reading data in columnar format, Spark benefits from enhanced performance across the board. For instance, larger file sizes typically result in better compression ratios, and querying specific columns becomes much faster as the system needs to load less data into memory.
ClickHouse
ClickHouse is an open-source columnar database management system that is specifically designed for online analytical processing (OLAP). ClickHouse fully utilizes vectorized query execution capabilities, leading to blazing-fast query responses even on massive datasets.
Writing Vectorized Queries in ClickHouse:
SELECT
AVG(column1), COUNT(*)
FROM
table_name
WHERE
column2 > 100
GROUP BY
column3
In ClickHouse, the engine executes queries using multiple threads, processing data in batches, which decreases the execution time significantly.
Optimizing Your Queries for Vectorized Execution
To fully leverage vectorized query execution, consider implementing the following best practices:
1. Choose the Right Data Layout
When working with large datasets, selecting an optimal storage format is crucial. Prefer columnar storage formats like Parquet or ORC (Optimized Row Columnar) that are designed for efficient analytics and support vectorized execution natively.
2. Filter Early
Implementing predicate pushdown can ensure that filters are applied as early as possible in the query execution process. This minimizes the amount of data processed in subsequent operations, enhancing overall performance.
3. Minimize Data Movement
Keeping data local to the processing engine reduces latency associated with data transfer. Ensuring that data is stored close to compute resources can help maintain high throughput during query execution.
4. Use Bulk Inserts
When ingesting large quantities of data, use bulk inserts instead of row-by-row operations. This takes advantage of vectorized execution by reducing the overhead associated with individual transaction management.
5. Profile and Optimize
Use profiling tools specific to your data processing framework to analyze and optimize your queries. Tools like Spark UI or ClickHouse’s system tables can reveal bottlenecks in query performance and suggest avenues for improvement.
Common Challenges with Vectorized Query Execution
While there are numerous benefits to vectorized query execution, there are also challenges that practitioners must navigate:
1. Learning Curve
Switching from traditional row-based processing to vectorized execution requires an understanding of new tools and frameworks. Users may need to invest time in learning to effectively implement vectorized queries.
2. Compatibility Issues
Not all frameworks support vectorized query execution natively. Users must ensure compatibility between their data storage methods and processing engines to achieve the desired performance improvements.
3. Resource Management
Vectorized execution can lead to increased memory usage due to the batching of data. Proper resource management is essential to prevent overwhelming system memory, especially when working with extremely large datasets.
Future of Vectorized Query Execution
The development of vectorized query execution is continually evolving, with trends pointing towards increased performance in data analytics. Technologies such as GPU acceleration and distributed processing frameworks are being integrated into modern data pipelines, further enhancing the potential for vectorized execution.
Moreover, as AI and machine learning grow increasingly reliant on large datasets, query processing systems are expected to prioritize vectorization techniques that can deliver rapid insights.
Investing time in understanding and implementing vectorized execution is crucial for data professionals looking to enhance their analytical capabilities and streamline data processing. As organizations strive for more agile analytics, vectorization will play a significant role in meeting these demands.
Leveraging vectorized query execution is essential for achieving faster Big Data analytics. By optimizing the processing of data in columnar format, organizations can significantly improve query performance and overall data processing speed. This approach enables efficient handling of large volumes of data, enhancing the scalability and effectiveness of Big Data analytics solutions. By implementing vectorized query execution techniques, organizations can unlock the full potential of their Big Data infrastructure and drive more insightful and timely decision-making processes.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works