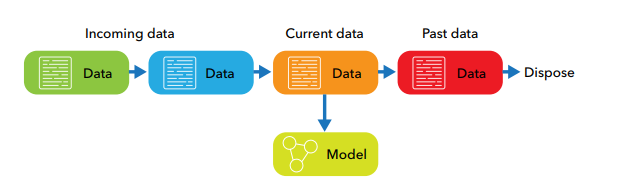
Implementing online machine learning on big data streams is a critical aspect of extracting valuable insights and patterns from massive amounts of data in real-time. As the volume and velocity of data continue to increase, traditional batch processing methods are no longer sufficient to keep up with the demands of processing and analyzing data in a timely manner. Online machine learning algorithms, which can learn and adapt to new data as it arrives, offer a promising solution to handle big data streams efficiently. In this context, leveraging the capabilities of big data technologies such as distributed computing frameworks and stream processing platforms is essential to successfully implement online machine learning on big data streams. This article will explore the key considerations and best practices for implementing online machine learning in the context of big data streams.
In today’s digital landscape, the surge in big data generation has led businesses to seek innovative solutions for real-time data processing. One such solution is online machine learning, which allows models to be trained incrementally on data streams as they arrive. This method is crucial for applications where timely insights are paramount, such as fraud detection, recommendation systems, and real-time analytics. Below, we explore the steps to effectively implement online machine learning on big data streams.
Understanding Online Machine Learning
Online machine learning differs from traditional batch learning in several key ways:
- Incremental Training: Models are updated continuously as new data arrives, enabling them to adapt to changes in the underlying data distribution.
- Memory Efficiency: Instead of storing large datasets, online learning algorithms process one sample at a time or a mini-batch, significantly reducing memory requirements.
- Real-Time Predictions: This approach allows for immediate updates and predictions, catering to applications that require swift response times.
Choosing the Right Tools and Frameworks
- Apache Kafka: A distributed event streaming platform that helps in handling real-time data feeds. It serves as the backbone for data ingestion in online learning systems.
- Apache Flink: A stream processing framework that offers capabilities for complex event processing and real-time analytics on big data streams.
- Apache Spark MLlib: Provides machine learning libraries that include algorithms suitable for online learning, making it easier to integrate with big data processing.
- TensorFlow: Features support for online learning through its support for continuous training and model saving/loading.
Data Ingestion from Big Data Streams
To implement online machine learning successfully, you need a robust strategy for data ingestion. Here’s a basic workflow:
- Source Identification: Determine the data sources, which can include social media feeds, financial transactions, sensor outputs, or web logs.
- Data Stream Processing: Utilize tools like Apache Kafka to collect and publish streams of data. This allows for a scalable architecture that can handle high throughput.
- Data Preprocessing: Clean and prepare data for analysis. This includes handling missing values, normalization, and feature extraction.
Example: In a fraud detection application, transactions can be streamed in real-time, processed to extract relevant features (e.g., transaction amount, time, location), and prepared for model training.
Model Selection for Online Learning
Choosing the right model is critical in online machine learning. Some common algorithms designed for online learning include:
- Stochastic Gradient Descent (SGD): Often used for linear classifiers and is effective in large scale and streaming scenarios.
- Hoeffding Trees: A special type of decision tree suited for making predictions based on data streams.
- Online Support Vector Machines (Svms): Efficiently updates the SVM model without needing to retrain on the entire dataset.
- Neural Networks with Online Learning: Using frameworks like TensorFlow, where models can be fine-tuned incrementally.
Implementing Online Learning Algorithms
Once the data ingestion and modeling strategy is in place, you can start implementing online learning algorithms. Here are the steps involved:
1. Initialize the Model
Start with a base model configuration. Ensure to specify hyperparameters relevant to the chosen algorithm.
2. Define Update Mechanism
Implement a method to handle real-time data and update the model. Typically, this can be done with a function that takes new data points, processes them, and updates model parameters accordingly.
3. Monitor Performance
It’s important to continuously track model accuracy and drift as new data comes in. Establish performance metrics that will indicate when the model is underperforming or needs retraining.
4. Handle Model Drift
Models can degrade over time due to changes in data characteristics (a phenomenon known as concept drift). Implementing solutions to detect and adapt to drift is essential. Techniques include:
- Utilizing drift detection algorithms such as the K-S test to identify changes.
- Setting a sliding window of data to regularly assess model performance against recent samples.
Deployment Considerations
Deploying your online machine learning model comes with its own sets of challenges. Here are some considerations to keep in mind:
- Scalability: Ensure that your architecture can scale with increasing data volume. Leverage cloud services or distributed computing solutions.
- Latency: Optimize the system to ensure real-time processing with minimal delay. This might involve streamlining data processing pipelines.
- Security: Implement robust security measures to protect data integrity and confidentiality especially in sensitive applications like fraud detection or healthcare.
- Version Control: Maintain versioning systems for models to revert to previous versions if current models underperform.
Testing and Evaluation
Thorough testing and evaluation are integral to the success of your online machine learning system. Utilize methods such as:
- A/B testing: Compare multiple versions of your model under identical conditions to assess which performs better.
- Backtesting: Implement historical data tests to validate model predictions against known outcomes.
- Cross-Validation techniques: Ensure that you validate the model performance under different subsets of data to gauge its reliability.
Conclusion
Implementing online machine learning on big data streams is no small feat, but with the right strategies, tools, and methodologies, businesses can leverage this powerful technology to gain real-time insights and stay ahead in a data-driven world. By meticulously executing each of the steps outlined above, you will be well-equipped to handle the complexities and demands associated with online learning in the context of big data.
Implementing online machine learning on big data streams is a critical aspect of leveraging the power of big data in real-time decision-making processes. By continuously updating models with new incoming data, organizations can extract valuable insights and make timely decisions to stay competitive in today’s data-driven world. The scalability, speed, and efficiency offered by online machine learning on big data streams present immense opportunities for businesses to optimize their operations and drive innovation.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 How Elasticsearch is Used in Big Data Applications
How Elasticsearch is Used in Big Data Applications