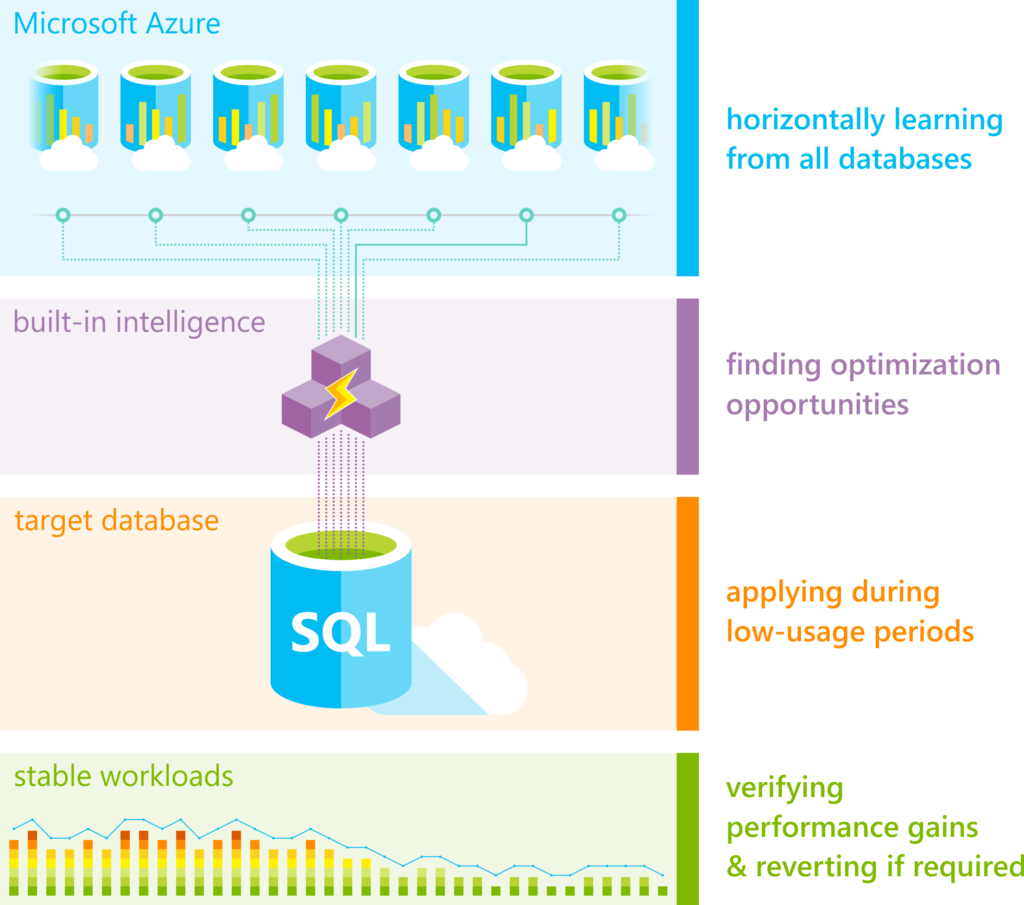
Implementing self-tuning databases for big data workloads is essential for optimizing performance and efficiency in handling massive volumes of data. Self-tuning databases utilize artificial intelligence and machine learning algorithms to automatically adjust configurations and parameters based on workload demands and data characteristics. This proactive approach enables the database to adapt dynamically to changing conditions, ensuring optimal performance without the need for manual intervention. In this article, we will explore the benefits of implementing self-tuning databases for big data workloads and provide insights on best practices for leveraging this technology to enhance scalability, reliability, and overall efficiency in managing big data environments.
Understanding Self-Tuning Databases
A self-tuning database autonomously adjusts its parameters and configurations to optimize its performance for varying workloads. In the context of big data, where datasets are large and constantly changing, self-tuning capabilities can significantly enhance system efficiency and responsiveness.
Benefits of Self-Tuning for Big Data Workloads
Implementing a self-tuning database brings a multitude of advantages to big data workloads, including:
- Improved Performance: Automated optimizations lead to enhanced response times.
- Reduced Administrative Overhead: Less manual intervention is required, allowing DBAs to focus on strategic tasks.
- Adaptive Learning: Self-tuning databases evolve and improve based on historical workload patterns.
- Cost Management: Efficient resource utilization can reduce operational costs over time.
Key Metrics for Self-Tuning Databases
To successfully implement a self-tuning database, it’s vital to track several key performance metrics:
- Query Latency: Measure the time taken for queries to return results.
- Throughput: Assess the number of transactions processed in a given time frame.
- Resource Utilization: Monitor CPU, memory, and disk usage to ensure optimal resource allocation.
- Error Rates: Track the rate of errors and failures to identify performance dips or misconfigurations.
Strategies to Implement Self-Tuning Databases
1. Evaluate Database Management Systems (DBMS)
Begin by selecting a DBMS that supports self-tuning features. Prominent technologies include:
- Oracle Autonomous Database: Uses machine learning to automate routine database tasks.
- Amazon Aurora: Provides self-healing capabilities and automatic scaling for big data applications.
- IBM Db2: Offers auto-tuning capabilities with built-in optimization algorithms.
Review detailed documentation and community feedback about the suitability of these systems for your specific workload needs.
2. Analyze Your Current Workloads
A comprehensive analysis of your existing workloads is fundamental for successful implementation. Key tactics include:
- Workload Profiling: Identify patterns in data access, query frequency, and resource utilization.
- Data Classification: Segment data based on frequency of access, size, and type.
- Identify Bottlenecks: Use monitoring tools to analyze performance bottlenecks within your current database setup.
3. Setting Up Performance Benchmarks
Establish performance benchmarks by running standard workload queries to gauge the initial performance. This will serve as a baseline for subsequent optimizations. Key considerations include:
- Expected Latency: Define acceptable response times for various query types.
- Resource Thresholds: Determine critical thresholds for CPU and memory usage.
- Quality of Service (QoS) Levels: Establish different tiers for database responsiveness and availability based on business requirements.
4. Implement Auto-Tuning Mechanisms
Integrate tools and configurations that allow self-tuning capabilities, such as:
- Query Re-Optimizer: Automatically refines execution plans based on workload patterns.
- Index Management: Periodically evaluates and modifies indexing strategies based on usage patterns.
- Storage and Resource Scaling: Set up automatic scaling configurations for storage and compute resources.
5. Use Machine Learning for Optimization
To leverage the full potential of big data, consider machine learning algorithms that can analyze historical performance data:
- Predictive Analytics: Anticipate future workload demands and adjust configurations accordingly.
- Anomaly Detection: Identify outliers in performance that may indicate issues with the self-tuning mechanisms.
- Continuous Learning: Implement model retraining strategies that allow the system to improve over time through learned experiences.
Best Practices for Self-Tuning Database Implementation
1. Continuous Monitoring and Feedback Loops
Establish continuous monitoring mechanisms to gather performance data. Ensure feedback loops are in place to allow the system to adjust itself based on real-time data. Key technologies include data monitoring dashboards and alert systems that inform DBAs of significant deviations from expected performance metrics.
2. Regularly Update Database Engine and Tools
Ensure your database engine and tuning tools are regularly updated to leverage new features, security patches, and performance enhancements. Consult user forums and industry publications to stay informed about advancements in self-tuning technologies.
3. Train Your Team
Invest in proper training for your database administration and data analysis teams. Familiarity with self-tuning database features will empower them to optimize the system effectively. Encouraging participation in workshops and certification programs can further enhance skills.
4. Conduct Periodic Reviews and Adjustments
Regularly review the effectiveness of self-tuning functions. Set up scheduled meetings to discuss tuning performance and make necessary adjustments to parameters, configurations, and strategies. Document changes and lessons learned for future reference.
Common Pitfalls to Avoid
1. Over-Reliance on Automation
While self-tuning databases reduce manual overhead, over-reliance can lead to complacency. Maintain a hands-on approach to regularly review system performance and address issues that may not be captured by automatic features.
2. Failure to Adapt to Changing Workloads
Data workloads can evolve rapidly. Ensure the tuning mechanisms are flexible and can adapt to shifting workload profiles and changes in user behavior to prevent performance degradation.
3. Neglecting Security Considerations
Automated systems can inadvertently expose vulnerabilities. Conduct regular security assessments to ensure that self-tuning actions do not compromise your data integrity, confidentiality, and compliance with relevant regulations.
Conclusion
Implementing a self-tuning database can optimize your big data workloads, significantly enhancing operational performance and efficiency. By understanding the requirements, measuring key metrics, and following structured implementation strategies, organizations can effectively harness the power of self-tuning databases.
Implementing self-tuning databases for big data workloads offers a promising solution to automate performance optimization and scalability challenges in managing large volumes of data. By leveraging machine learning algorithms and automation capabilities, organizations can achieve efficient data management, improved query performance, and enhanced resource utilization, ultimately driving better decision-making and productivity in the realm of big data analytics.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 The Evolution of Big Data Technologies: Past, Present, and Future
The Evolution of Big Data Technologies: Past, Present, and Future
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics