In the fast-paced world of Big Data, maintaining model accuracy can be a significant challenge due to the dynamic nature of the data environment. Data drift, the phenomenon where the statistical properties of the data change over time, can have a detrimental impact on the performance of machine learning models. To address this issue, data drift detection techniques play a crucial role in continuously monitoring and adapting models to ensure accuracy and reliability. By leveraging these tools effectively, organizations can proactively identify and mitigate data drift, ultimately enhancing the overall performance and effectiveness of their Big Data models.
In the vast world of Big Data, maintaining the accuracy of machine learning models is paramount. As data evolves, the risk of data drift increases, which can lead to degraded model performance. This article explores the significance of data drift detection and offers actionable strategies for leveraging it to ensure model accuracy.
Understanding Data Drift
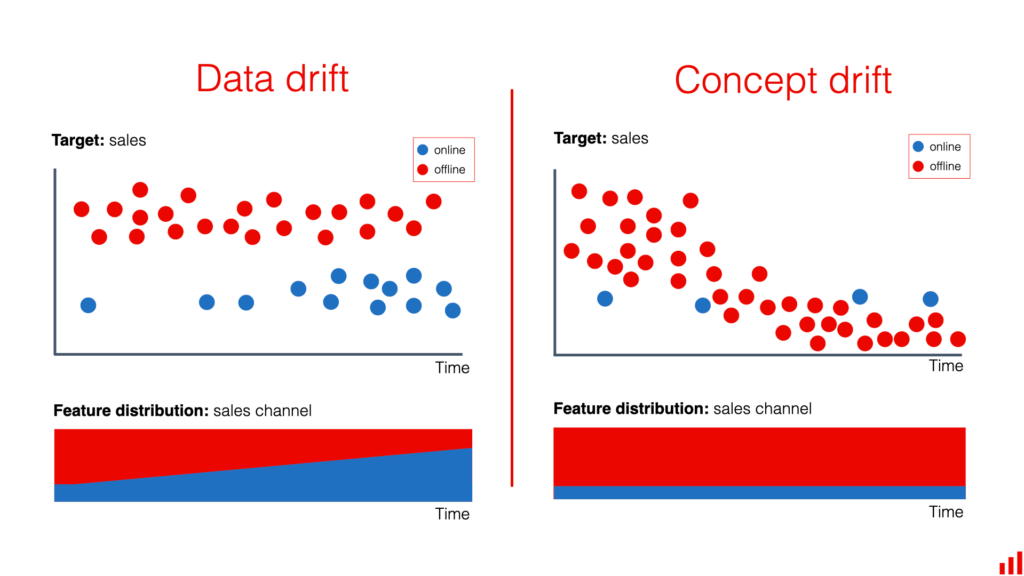
Data drift refers to changes in the statistical properties of target variables and input features over time. It can significantly affect the performance of machine learning models, especially when they were trained on static datasets. Understanding data drift is essential for data scientists and machine learning engineers, as it can lead to inaccurate predictions and undermine the value of insights derived from big data.
Types of Data Drift
There are primarily two types of data drift:
- Covariate Shift: This occurs when the distribution of the input features changes, while the conditional distribution of the target variable given the input remains constant.
- Prior Probability Shift: This happens when the distribution of the target variable changes. In this case, both the feature distribution and the target variable distribution are altered.
Recognizing these types of drift is crucial as they necessitate different detection strategies and remediation measures.
The Importance of Data Drift Detection
Detecting data drift is vital for several reasons:
- Model Performance: Drifts directly affect the model’s predictive accuracy, necessitating timely adjustments to maintain performance.
- Resource Optimization: Identifying drifts allows for the efficient allocation of computational and human resources, focusing efforts where they are needed most.
- Business Insights: Understanding drift helps maintain reliable analytics, leading to better decision-making based on accurate data interpretations.
Methods for Detecting Data Drift
Several methods can be employed to detect data drift. Below are some popular techniques used by practitioners in the field:
1. Statistical Tests
Statistical tests allow you to compare the distributions of data over time using techniques like:
- Kolmogorov-Smirnov Test: This test assesses whether two samples come from the same distribution. It’s effective for detecting covariate shifts.
- Chi-Squared Test: Useful for categorical data, the Chi-Squared test evaluates the differences between observed and expected frequencies.
2. Model Performance Monitoring
Continuously monitor your model’s performance on live data. Metrics such as accuracy, recall, and AUC can serve as indicators of drift. A significant deviation in these metrics over time can indicate a need to investigate data drift.
3. Drift Detection Algorithms
There are specialized algorithms designed for drift detection:
- Drift Detection Method (DDM): This algorithm monitors the performance of a model and flags when performance drops below a certain threshold.
- Early Drift Detection Method (EDDM): An extension of DDM, EDDM is particularly sensitive to minor drifts in data distribution.
4. Monitoring Feature Statistics
Track the summary statistics (mean, median, standard deviation) of your features over time. Significant changes in these statistics could be a sign of data drift.
Implementing Data Drift Detection in Practice
To effectively implement data drift detection, follow these steps:
1. Establish a Baseline
Start by collecting a comprehensive dataset to establish a baseline for your model. This dataset will serve as the reference point for future comparisons.
2. Choose the Right Metrics
Select appropriate performance metrics that align with your business objectives. This ensures any drift detected will be relevant to the impact on your business’s performance.
3. Automate Monitoring
Use automated monitoring tools to regularly check for data drift. Automated systems can alert data scientists and engineers when drift is detected, allowing for prompt action.
4. Periodic Model Retraining
Establish a schedule for retraining your models based on drift detection. When significant drift is detected, update your model with newly available data to maintain accuracy.
Leveraging Big Data Tools for Drift Detection
Several tools and platforms can assist in monitoring data drift effectively:
- Apache Kafka: Useful for real-time data streaming and processing. Kafka can help in tracking incoming data and its statistical properties.
- TensorFlow Data Validation (TFDV): A tool specifically designed to analyze and validate machine learning data, which includes functionality to detect drift.
- Prometheus: This open-source monitoring tool can be configured to keep track of performance metrics and alert for drift-related issues.
Integrating Drift Detection into the ML Lifecycle
It’s essential to integrate drift detection into your machine learning lifecycle. Here’s how:
1. Data Ingestion
Implement drift detection mechanisms during the data ingestion phase. This will allow you to catch drift early before it impacts model performance.
2. Model Training and Validation
Incorporate drift detection checks during model training and validation phases. This enables better understanding and adjustments to underlying features or algorithms if drift is detected.
3. Model Deployment
Once deployed, continue monitoring the model’s performance and data characteristics in real-time to ensure stability and reliability.
4. Continuous Feedback Loop
Create a feedback loop where insights gained from drift detection inform future model training and feature selection processes.
Challenges in Data Drift Detection
While several methods exist for detecting data drift, practitioners may face challenges such as:
- High Dimensionality: Dealing with high-dimensional data can complicate drift detection efforts, making it difficult to draw meaningful conclusions.
- Noise in Data: Fluctuations in data can obscure true signals of drift, necessitating robust statistical techniques to minimize noise influence.
- Sparsity of Data: In some cases, low volumes of data may limit the ability to perform effective drift detection analyses.
Future Directions in Data Drift Detection
The field of data drift detection is rapidly evolving, with new methodologies continually emerging. Future trends may include:
- AI and Machine Learning Models: The use of AI to automatically detect and respond to drift could revolutionize how organizations approach data quality.
- Integration with MLOps Practices: As organizations adopt MLOps, embedding drift detection into CI/CD pipelines will streamline monitoring and retraining processes.
- Enhanced Visualization Tools: Beyond raw data, better visualization tools can help data scientists understand drift more intuitively.
Utilizing effective data drift detection methods is crucial for maintaining the integrity of machine learning models in big data environments. As data continues to grow and evolve, proactive measures will ensure that models remain relevant and accurate, delivering invaluable insights that drive informed decision-making.
In the context of Big Data, leveraging data drift detection techniques is crucial for maintaining model accuracy over time. By continuously monitoring and adapting to changes in data distribution and patterns, organizations can ensure their models remain effective and reliable in dynamic environments. Proactive management of data drift enables better decision-making and minimizes the risk of inaccurate predictions or biases in Big Data applications.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data