Large-scale knowledge distillation is a pivotal technique in AI model compression that plays a crucial role in leveraging Big Data for creating more efficient and streamlined machine learning models. By distilling knowledge from large, complex models into more compact versions without compromising performance, knowledge distillation allows organizations to reduce computational costs and deploy models more effectively in resource-constrained environments, ultimately leading to accelerated innovation and adoption of AI technologies. In this article, we explore the significance of large-scale knowledge distillation in the context of Big Data and how it enables the creation of powerful yet lightweight AI models suitable for various real-world applications.
In the rapidly evolving landscape of artificial intelligence (AI) and big data, model compression has emerged as a critical area of research and application. Large-scale knowledge distillation is a pivotal technique that facilitates the effective compression of AI models while maintaining performance levels. This article explores the intricacies of this approach and its significant implications for big data processing.
Understanding Knowledge Distillation
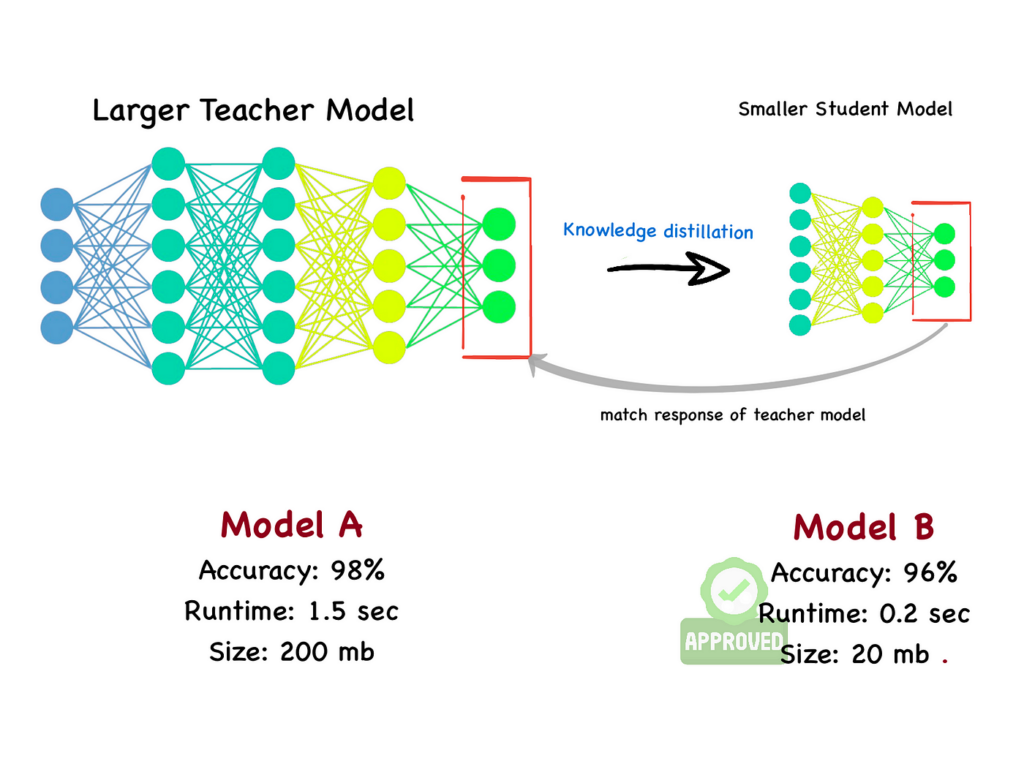
Knowledge distillation is a method of transferring the knowledge from a large, complex model (often referred to as the teacher model) to a smaller, more efficient model (known as the student model). This process allows the student model to learn not just from the final output of the teacher model but also from its intermediate representations. Thus, the efficiency of AI systems can be enhanced without a significant trade-off in performance.
The essence of knowledge distillation lies in its ability to simplify models without sacrificing accuracy, which is crucial when dealing with massive datasets commonly found in big data environments. As organizations increasingly harness large volumes of data to train complex models, the need for efficient data processing becomes paramount.
Why Model Compression is Essential in Big Data
Big data environments typically involve vast datasets that require substantial computational resources. Large models, while powerful, often demand more memory and processing capability, making them impractical for deployment in resource-constrained settings. Here are some reasons why model compression through knowledge distillation is vital:
- Resource Efficiency: Compressed models are less memory-intensive and require lower computational resources, enabling deployment on devices with limited processing power, such as mobile phones and IoT devices.
- Faster Inference Times: Smaller models translate to faster inference, which is essential in real-time applications where decisions need to be made quickly.
- Lower Latency: In big data applications, low latency in processing can significantly impact performance, making model compression crucial.
- Reduced Power Consumption: Smaller models consume less energy, which is a critical factor in scaling up AI applications.
Mechanics of Large-Scale Knowledge Distillation
Large-scale knowledge distillation involves several steps to ensure that the student model extracts the necessary information from the teacher model effectively. Let’s explore these steps:
1. Dataset Preparation
Before initiating the distillation process, it is essential to prepare a suitable dataset. This dataset could be the same as the one used for training the teacher model or a new one that reflects the distribution of incoming data in production. Quality and diversity in the training dataset are paramount for achieving optimal performance in the distilled model.
2. Training the Teacher Model
The teacher model, typically a deep neural network with numerous layers and parameters, is trained on the prepared dataset. This model learns to make predictions by uncovering complex patterns within the data. It serves as the benchmark for the performance that the student model will aim to achieve.
3. Generating Soft Targets
Once the teacher model is trained, it generates soft targets—probabilities representing the likelihood of each class for every sample in the validation set. These soft targets convey more information than hard labels, allowing the student model to capture the nuances of the teacher model’s predictions.
4. Training the Student Model
The student model is then trained using both the soft targets from the teacher model and the original hard labels. This dual training process enables the student model to learn from the rich information provided by the teacher model while ensuring that it is still accountable to the original task.
5. Fine-tuning and Evaluation
After training, the student model undergoes fine-tuning, where hyperparameters can be adjusted to further optimize performance. The final step involves evaluating the student model on a separate test dataset to ensure that it meets the required performance benchmarks.
Advantages of Large-Scale Knowledge Distillation
Large-scale knowledge distillation presents a myriad of advantages, especially in the context of big data:
1. Scalability
Innovatively compressing models allows for scalability, making it feasible to deploy various models across different platforms and devices. Organizations can efficiently handle increasing amounts of data without a proportional increase in resource consumption.
2. Versatility
The distillation process is versatile and can be applied across different types of models (e.g., convolutional neural networks, recurrent neural networks) and use cases. This adaptability ensures that various big data applications can benefit from model compression.
3. Performance Preservation
While the student model is smaller, its ability to replicate the teacher model’s performance closely allows organizations to retain competitive advantages. The key lies in the distillation process, which maintains the model’s interpretability and decision-making capabilities.
4. Enhanced Transfer Learning
Knowledge distillation enhances transfer learning by enabling models to generalize better on new tasks. It allows the distillation of knowledge across different domains, making it easier to adapt large models trained on specific datasets to other applications with limited data.
Challenges and Considerations
Despite its notable advantages, large-scale knowledge distillation does come with its challenges:
1. Complexity of Teacher Models
Designing and training a robust teacher model can be resource-intensive, both in terms of time and computational costs. For organizations with limited resources, this can present a significant barrier to successful distillation.
2. Overfitting of the Student Model
There is a risk that the student model may overfit to the soft targets provided by the teacher model if not properly monitored. Appropriate regularization techniques must be employed to mitigate this risk.
3. Dependency on Quality of Teacher Models
The effectiveness of the student model relies heavily on the performance of the teacher model. If the teacher model has weaknesses or biases, these issues can be transferred to the student model.
The Future of Large-Scale Knowledge Distillation
As big data continues to expand, large-scale knowledge distillation is poised to become increasingly significant. The rise of edge computing and the Internet of Things (IoT) will necessitate the development of more compact and efficient models. Future research will likely focus on:
- Improving Distillation Techniques: Advanced methodologies to create even smaller and more efficient models without compromising accuracy.
- Automated Distillation Frameworks: Tools and frameworks that streamline the distillation process, enabling organizations to utilize the technology with minimal manual intervention.
- Integrating with Other AI Techniques: Combining knowledge distillation with other AI model optimization strategies, such as pruning and quantization, to create highly efficient models.
In summary, large-scale knowledge distillation plays an essential role in the realm of AI model compression related to big data. By optimizing models for efficiency and effectiveness, organizations can continue to harness the true potential of big data without overwhelming their computing resources.
Large-scale knowledge distillation plays a crucial role in compressing AI models in the realm of Big Data, enabling more efficient and scalable utilization of computational resources while maintaining high performance levels. This innovative approach offers a promising solution to the challenges of deploying and managing complex AI models at scale, making it a valuable tool for organizations seeking to leverage the power of Big Data for various applications.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data