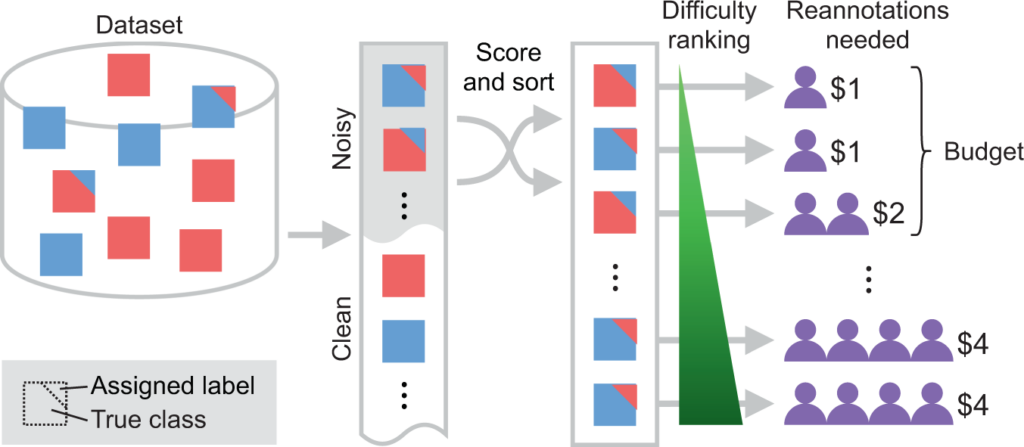
In the realm of Big Data analytics, the quality and reliability of data play a critical role in the accuracy of subsequent analyses and decision-making processes. One common challenge faced by organizations working with large datasets is the presence of label noise — inaccuracies or inconsistencies in the data labeling process. To address this issue, the integration of Artificial Intelligence (AI) into data cleaning procedures has emerged as a powerful tool. By utilizing AI algorithms to detect and correct label noise, organizations can significantly enhance the quality of their datasets, leading to more reliable insights and improved outcomes. This article explores the importance of AI-enhanced data cleaning in mitigating label noise within the context of Big Data analytics.
In the world of Big Data, the quality of data plays a critical role in the effectiveness of analytics and machine learning models. One of the most significant issues that data scientists encounter is label noise, which can severely impact the outcomes of models trained on inaccurate or misleading data. As organizations continue to accumulate vast amounts of data, the need for robust data cleaning techniques has never been more important. AI-enhanced data cleaning has emerged as a powerful tool to address the challenges of label noise.
Understanding Label Noise in Big Data
Label noise refers to the inaccuracies or inconsistencies found in the labels assigned to data points—essentially, the output variable in supervised learning tasks. Different types of label noise include:
- Random Noise: Labels that are purely incorrect due to random mistakes, often arising from manual data entry or mislabeling.
- Systematic Noise: Inaccuracies that appear due to systemic flaws in the labeling process or biases in the data collection methods.
- Ambiguity Noise: Scenarios where the true label of a data point is uncertain, causing disagreements among different labelers.
Label noise can lead to misleading model performance evaluations, incorrect predictions, and ultimately compromised decision-making processes. Reducing label noise is, therefore, a fundamental challenge when working with big data.
The Importance of Data Cleaning in Big Data
Data cleaning is the process of detecting and correcting (or removing) corrupt or inaccurate records from a dataset. Effective data cleaning is essential for enabling organizations to derive valuable insights from their data. The key reasons data cleaning is important include:
- Improved Model Accuracy: Clean data increases the accuracy of machine learning models, ensuring that they can make reliable predictions based on the training data.
- Enhanced Decision-Making: Clean data fosters data-driven decision-making by providing accurate information essential for strategy formulation and execution.
- Operational Efficiency: Proper data cleaning processes streamline data management and reduce the overhead associated with dealing with data quality issues.
Challenges of Traditional Data Cleaning Methods
Traditional data cleaning techniques often struggle with the complexity and scale of big data. Some of the challenges include:
- Manual Effort: Many traditional methods rely on manual intervention, which is time-consuming and prone to human error.
- Scalability: Traditional systems may struggle to handle large volumes of data effectively, leading to bottlenecks and delays in the data cleaning process.
- Lack of Adaptability: Traditional methods are less adaptable to evolving data patterns and complexities, making it harder to address label noise in dynamic environments.
The Emergence of AI in Data Cleaning
AI technologies, including machine learning and natural language processing, have revolutionized the way data cleaning is approached. Here’s how AI enhances the data cleaning process:
- Automated Correction: AI algorithms can automatically detect and correct inaccuracies within datasets without extensive human input, significantly reducing time spent on data cleaning.
- Pattern Recognition: AI models excel at identifying patterns and anomalies, helping distinguish between accurate labels and noisy labels more effectively.
- Learning from Data: AI systems can continuously learn from ongoing data interactions, improving their data cleaning techniques over time and adapting to new noise patterns.
How AI-Enhanced Data Cleaning Reduces Label Noise
AI-enhanced data cleaning plays a crucial role in mitigating label noise in several important ways:
1. Advanced Anomaly Detection
AI algorithms implement advanced techniques for anomaly detection to identify outliers and inconsistencies within labeled data. By deploying methods such as clustering and classification, AI can effectively separate true data points from corrupted or misclassified ones. This ensures that even small amounts of labeled data can be validated against the overall dataset.
2. Intelligent Data Imputation
AI systems are capable of employing intelligent data imputation strategies that help fill gaps where data may be missing or misclassified. Techniques such as K-Nearest Neighbors (KNN) or iterative imputation use the relationships and patterns identified in the data, allowing for more informed assumptions to be made about mislabeling.
3. Label Noise Recognition through Semi-Supervised Learning
Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data. This approach helps models learn to identify which data points are likely to be noisy, reducing the likelihood of using incorrect labels for training. By leveraging both types of data, the model can make more accurate predictions while demystifying the complexities involved in existing data.
4. Continuous Feedback Loop
AI systems can create a continuous feedback loop that identifies and corrects labeling errors over time. By integrating user feedback and model predictions, organizations can refine their labeling processes, subsequently enhancing the overall quality of their datasets. This adaptive cycle helps ensure that the data cleaning process is always targeting the most relevant sources of label noise.
Implementing AI-Enhanced Data Cleaning
To take advantage of AI-enhanced data cleaning, organizations should consider the following steps:
- Data Assessment: Conduct thorough evaluations of existing datasets to identify sources and types of label noise present.
- Invest in AI Tools: Leverage AI-powered tools and platforms that specialize in data cleaning and can integrate seamlessly into existing workflows.
- Training and Development: Train data scientists and engineers in the use of AI methods for data cleaning to ensure they can effectively deploy these technologies.
- Monitoring and Feedback: Establish a framework for ongoing monitoring and feedback collection to continually improve data quality over time.
Conclusion
The integration of AI-enhanced data cleaning technologies represents a significant advancement in the quest to reduce label noise in big data environments. By addressing the limitations of traditional data cleaning methods, organizations can achieve higher data quality, leading to more accurate model predictions and better-informed decision-making processes.
As big data continues to evolve, the role of AI in enhancing data cleaning will be increasingly critical. Organizations that invest in these advanced methodologies will not only improve their data quality but also maintain a competitive edge in their respective industries.
The incorporation of AI-enhanced data cleaning techniques plays a critical role in mitigating label noise and improving data quality in the realm of Big Data. By effectively identifying and correcting errors in labeling, AI algorithms enable more accurate and reliable decision-making processes, ultimately enhancing the value and utility of Big Data analytics.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 How Elasticsearch is Used in Big Data Applications
How Elasticsearch is Used in Big Data Applications