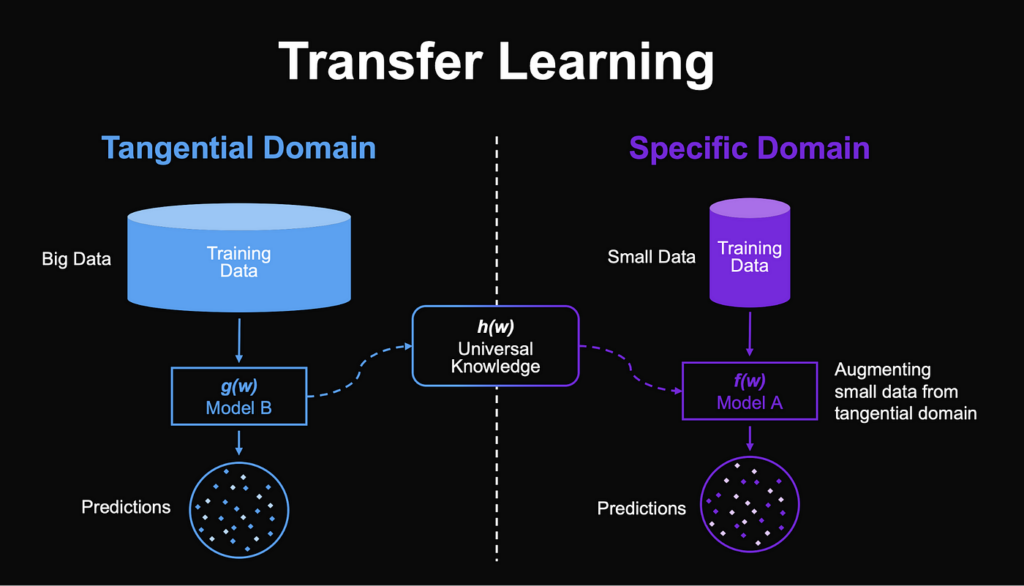
Domain adaptation is a crucial technique in the realm of Big Data artificial intelligence (AI) models, enabling these models to perform effectively across different domains or datasets. In the era of Big Data, where vast amounts of varied data are generated and collected, domain adaptation ensures that AI models can generalize well and make accurate predictions even when faced with new or unseen data sources. By understanding how to perform domain adaptation for Big Data AI models, businesses and researchers can enhance the robustness and applicability of their AI systems, leading to more reliable insights and decision-making processes.
In the world of Big Data, the ability to adapt AI models to different domains is crucial for ensuring their effectiveness. Domain adaptation is a subfield of transfer learning that aims to tackle the challenge of training models on a source domain and deploying them in a target domain, which may have different data distributions. This article provides an in-depth look at how to perform domain adaptation for Big Data AI models, incorporating strategies, techniques, and tools that can enhance performance.
Understanding Domain Adaptation
At its core, domain adaptation involves adjusting a model trained on a source dataset to perform well on a related target dataset. This is particularly important in Big Data contexts, where collecting and labeling data can be expensive and time-consuming. The objective is to improve model generalization to accommodate variations in data distributions.
Key Concepts in Domain Adaptation
- Source Domain: The domain from which the model is initially trained, characterized by labeled data.
- Target Domain: The domain to which the model is applied, often containing less or no labeled data.
- Domain Shift: The difference in data distribution between the source and target domains.
- Feature Space: The representation of data features in the model.
Steps to Perform Domain Adaptation
1. Data Collection and Preprocessing
Start by gathering data from both the source and target domains. For effective data preprocessing, follow these steps:
- Data Cleaning: Remove duplicates, handle missing values, and correct inconsistencies.
- Feature Selection: Identify the most relevant features that contribute to model performance.
- Normalization: Scale the features to a uniform range to facilitate model training.
2. Exploratory Data Analysis (EDA)
Before diving into domain adaptation techniques, perform EDA to understand the distributions of both domains. Analyze:
- Statistical properties (mean, variance, etc.)
- Correlation between features
- Visualizations (box plots, histograms, etc.)
EDA helps you identify the necessary adaptations and informs decisions on the appropriate machine learning algorithms to use.
3. Choose the Right Domain Adaptation Technique
There are multiple strategies for domain adaptation, each tailored to specific scenarios:
- Instance-based Adaptation: Adjust the weights of instances in the source domain to make them more similar to the target domain. Techniques like re-weighting and importance sampling can be employed here.
- Feature-based Adaptation: Transform the feature space to minimize the discrepancy between source and target distributions. Approaches include:
- Principal Component Analysis (PCA): Reduces dimensionality while preserving variance.
- Domain Adversarial Neural Networks (DANN): Uses adversarial training to learn domain-invariant features.
- Model-based Adaptation: Fine-tune the pre-trained model on a small labeled subset from the target domain. This can improve performance with limited data.
4. Implementing Domain Adaptation Algorithms
Once you have selected the appropriate method, implement the chosen algorithms using relevant programming languages and libraries such as Python, TensorFlow, or PyTorch.
import torch
import torch.nn as nn
from torch.optim import Adam
from torchvision import datasets, transforms
# Example code for a simple DANN implementation
class DANN(nn.Module):
# Define the model architecture
pass
# Training loop for DANN
def train_dann(model, source_loader, target_loader):
# Implementation of the training loop
pass
5. Evaluation of Domain Adaptation Performance
After training your model, it’s crucial to evaluate its performance on the target domain. Use metrics such as:
- Accuracy: To measure overall success.
- Precision, Recall, and F1-Score: For more granular assessment, especially in imbalanced datasets.
- Confusion Matrix: To visualize prediction outcomes.
Comparing results against a baseline model trained solely on the source domain can reveal the effectiveness of your adaptation strategy.
6. Continuous Learning and Adaptation
Domain adaptation is not a one-time process. As new data arrives in the target domain, continuously updating your model can greatly improve its relevance and accuracy. Implementing a system for ongoing learning will help maintain model performance over time.
Challenges in Domain Adaptation for Big Data AI Models
1. Data Availability and Quality
One major challenge is availability and the quality of labeled data in the target domain. In many cases, data may be sparse or noisy, making it difficult to achieve good model performance.
2. Complexity of Domain Shift
Significant differences in the input data distributions can complicate domain adaptation. Understanding the underlying causes of domain shift is crucial for selecting the right adaptation strategy.
3. Computational Resources
Big Data workflows can demand extensive computational resources, particularly with advanced techniques like deep learning. Efficiently managing resources and optimizing algorithms remain critical challenges.
Tools and Libraries for Domain Adaptation
There are several tools and libraries available that can assist with domain adaptation in Big Data AI models. Some of the most popular include:
- TensorFlow: Offers robust support for building and deploying machine learning models, including various domain adaptation techniques.
- Pytorch: Provides greater flexibility in defining custom models and optimizing them through gradient descent.
- Transfer Learning Libraries: Libraries like Keras or Fastai come with pre-trained models and functions tailored for transfer learning.
Conclusion
Implementing domain adaptation for Big Data AI models can be a daunting task, yet it is essential for achieving high-performance results across varying domains. Understanding the necessary steps, techniques, and tools lays down a framework for effectively navigating this complex landscape. By consistently refining your approach and leveraging state-of-the-art methods, you can significantly enhance your model’s capability to adapt and perform in diverse settings.
Domain adaptation is essential in maximizing the performance of Big Data AI models by addressing shifts in data distribution across different domains. By leveraging techniques such as transfer learning and adversarial training, organizations can effectively adapt their models to new domains without the need for large labeled datasets. This enables the seamless integration of Big Data AI models across diverse applications and domains, ultimately enhancing the overall accuracy and generalization capabilities of the models in the realm of Big Data.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data