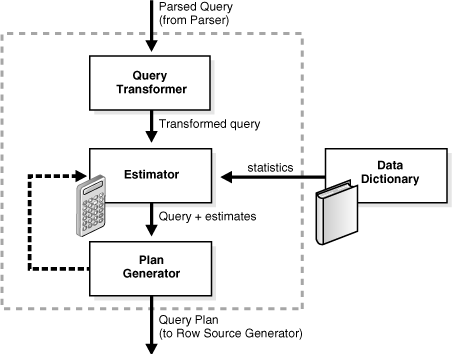
Optimizing query performance is crucial in the realm of Big Data to ensure efficient data processing and retrieval. Implementing auto-tuning of query optimizers can significantly enhance the performance of database systems handling vast amounts of data. By leveraging advanced algorithms and machine learning techniques, auto-tuning can dynamically adjust query execution plans based on data statistics and workload patterns. This approach not only optimizes performance but also adapts to changing data characteristics in real-time. In this article, we will explore the importance of auto-tuning query optimizers in the context of Big Data and discuss strategies for successfully implementing this optimization technique.
In the realm of Big Data, efficient query optimization is crucial for performance enhancement and resource management. As data volume, variety, and velocity escalate, the need for dynamic and adaptive systems becomes evident. Auto-tuning of query optimizers greatly facilitates this necessity by allowing systems to self-adjust based on ongoing workload analysis. Below, we explore the detailed steps and considerations for implementing auto-tuning of query optimizers for Big Data environments.
Understanding Query Optimization in Big Data
At its core, a query optimizer is a component of database management systems that chooses the most efficient execution plan for a given query. In Big Data systems like Hadoop, Apache Spark, or Presto, optimizing queries becomes increasingly complex due to:
- High volume of data
- Diverse data formats
- Varied query patterns
Without effective optimization, querying large datasets can lead to resource exhaustion and suboptimal performance, making auto-tuning a valuable approach.
Steps for Implementing Auto-Tuning
1. Assess Current Query Performance
Before embarking on auto-tuning, it is imperative to establish a baseline of current query performance. This involves:
- Collecting performance metrics across workloads, such as execution time, memory usage, and CPU utilization.
- Identifying frequently executed queries and those that consume excessive resources.
Utilizing tools such as Apache Ambari or Prometheus for monitoring can provide insightful data on query behavior.
2. Analyze Workload Patterns
Understanding workload patterns is critical in predicting future query optimization needs. Some analytical strategies include:
- Using machine learning techniques to identify “hot” queries and establishing relationships between query patterns and system performance.
- Building usage profiles based on historical data to simulate various conditions and test how changes would impact performance.
3. Implement Adaptive Algorithms
With insights gained from performance and workload analysis, the next step is to implement adaptive algorithms. Here are common methods used in auto-tuning:
Feedback Control Loops
These loops continually assess query performance and adjust execution plans based on feedback. The algorithm can modify parameters, such as:
- Join strategies
- Index selections
- Data partitioning strategies
Cost-Based Optimization
Incorporate cost-based optimization techniques that account for various factors affecting performance like disk I/O, network latency, and data distribution. The optimizer can evaluate different execution plans, ensuring the one selected has the lowest estimated cost.
Machine Learning Models
Consider integrating machine learning models to predict the most suitable query execution strategies dynamically. These models can learn from historical data and adapt to changing workloads effectively.
4. Evaluate Parameter Tuning
Parameter tuning is an essential aspect of auto-tuning. Key parameters include:
- Memory allocation for query execution
- Configuration settings for parallel processing
- Buffer sizes for input/output operations
Using techniques like grid search or random search can help identify the optimal parameter settings by balancing performance and resource usage.
5. Testing and Validation
Once implementations are in place, rigorous testing and validation are necessary. Considerations should include:
- Running production-like workloads in a testing environment.
- Benchmarking against the baseline performance metrics established.
Employ A/B testing to compare different configurations and validate the effectiveness of the tuning approach.
Tools and Technologies for Auto-Tuning
Several tools and technologies can assist in the implementation of auto-tuning for Big Data query optimizers:
- Apache Hive – With its cost-based optimizer and various parameter tuning capabilities.
- Apache Spark – Utilizes Catalyst Optimizer, which can benefit from auto-tuning strategies.
- Presto – Works well with large data lakes and allows for dynamic resource allocation.
- MySQL Tuner – Specifically useful in relational databases for performance tuning.
Challenges in Auto-Tuning Query Optimizers
While the benefits of auto-tuning are substantial, several challenges accompany the implementation:
- Complexity of Workload Variability – Different workloads can dramatically shift performance metrics, making it challenging to develop a one-size-fits-all tuning strategy.
- Resource Overhead – The auto-tuning process itself may consume additional resources, necessitating an equilibrium between tuning efforts and resources utilized.
- Data Privacy – Ensuring sensitive data is protected during the analysis process remains a top priority.
Best Practices for Successful Auto-Tuning
To maximize the success of your auto-tuning efforts, consider the following best practices:
- Establish clear performance goals before initiating the tuning process.
- Regularly review and update tuning strategies to accommodate changing workloads and data patterns.
- Engage cross-functional teams (data engineers, DBAs, and developers) to ensure comprehensive understanding and coverage of performance aspects.
- Continuously monitor and analyze the impact of tuning on overall system performance and user experience.
The Future of Auto-Tuning in Big Data
The landscape of Big Data is rapidly evolving, pushing the boundaries of what systems can achieve. Auto-tuning of query optimizers stands at the forefront, driven by advancements in artificial intelligence and machine learning.
As we harness the full potential of auto-tuning, we can anticipate more intelligent systems that not only adapt to user needs in real-time but also provide significant savings in operational costs and improved resource utilization.
By embracing automated solutions, organizations can accelerate innovation and unlock valuable insights from their data investments.
Implementing auto-tuning of query optimizers for Big Data is crucial for maximizing performance and efficiency in processing large datasets. By utilizing automated techniques to fine-tune query optimization parameters, organizations can significantly improve query execution times and resource utilization, ultimately enhancing their overall Big Data analytics capabilities. It is imperative for businesses to embrace and leverage these advancements in order to stay competitive and derive valuable insights from their vast amounts of data.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 How Elasticsearch is Used in Big Data Applications
How Elasticsearch is Used in Big Data Applications
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models