In the era of Big Data, building an event-driven analytics architecture has become essential for organizations to derive valuable insights from massive amounts of data in real-time. This architecture leverages the power of Big Data technologies to process, analyze, and act upon events as they occur, enabling organizations to make data-driven decisions quickly and efficiently. By combining real-time event processing with Big Data analytics, businesses can extract meaningful patterns, trends, and correlations from their data, leading to improved decision-making, enhanced customer experiences, and competitive advantages. This article will explore the key components and considerations in developing an event-driven Big Data analytics architecture that can unlock the full potential of data for businesses.
Understanding Event-Driven Architecture (EDA)
The concept of Event-Driven Architecture (EDA) is foundational for building scalable and responsive big data analytics architectures. EDA involves the production, detection, consumption, and reaction to events—significant occurrences that convey information about system states. This architecture is particularly effective for applications that require real-time data processing and analytics.
Reasons to Choose an Event-Driven Architecture for Big Data Analytics
Utilizing EDA within your big data analytics framework brings several advantages:
- Scalability: EDA components can be scaled independently, allowing for enhanced performance under varying loads.
- Real-time Processing: The ability to react to events as they happen ensures timely insights.
- Loose Coupling: Components can interact with each other without tight dependencies, resulting in easier updates and maintenance.
- Enhanced Flexibility: Systems can adapt to new data sources or types of events without extensive redesign.
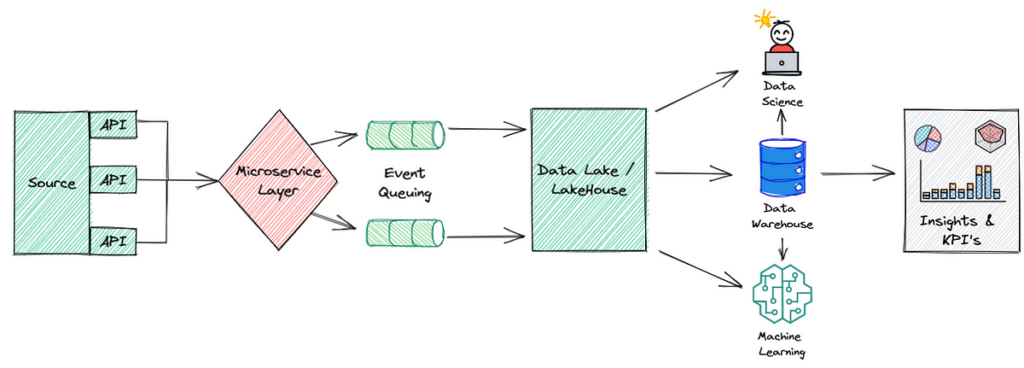
Key Components of an Event-Driven Big Data Analytics Architecture
A robust event-driven big data architecture typically comprises several key components:
1. Event Producers
Event Producers generate data as events occur. This can include IoT devices, web applications, user interactions, and enterprise systems. Each event contains relevant information that needs analysis.
2. Event Stream Processing Engines
The Event Stream Processing (ESP) Engine consumes and processes streams of events in real-time. Popular tools include Apache Kafka, Apache Flink, and Spark Streaming. They provide functionalities to filter, transform, and analyze event data seamlessly.
3. Event Storage
Event storage systems are essential for persisting events for later analysis or historical record-keeping. Solutions like Apache Cassandra, Amazon S3, and HDFS (Hadoop Distributed File System) serve to store structured and unstructured data.
4. Analytics Engines
Analytics Engines process stored data to extract insights and generate reports. This might involve batch processing with Apache Spark or operational analytics using tools like Elasticsearch for search capabilities.
5. Dashboards and Reporting Tools
Visualization is key in analytics. Tools like Tableau, Grafana, and Kibana gather and represent processed data, making it easier for stakeholders to interpret complex datasets.
Building the Architecture Step-by-Step
Step 1: Identify Event Sources
The first step in constructing an EDA for big data analytics is to identify your event sources. Determine the systems, devices, and applications that produce relevant events. This could include:
- Sensor data from IoT devices.
- User interactions on web platforms.
- Logs from traditional enterprise applications.
Step 2: Choose Your Event Messaging System
You will need a robust messaging system to ensure reliable event transmission. Apache Kafka is widely adopted for its ability to handle high throughput and durability. Other options worth exploring include RabbitMQ and AWS Kinesis.
Step 3: Implement Event Stream Processing
With your messaging in place, set up an event stream processing engine. This engine will filter and process incoming data. You can use:
- Apache Flink: Ideal for complex event processing and stateful streaming.
- Apache Spark Streaming: Great for integrating batch and real-time data processing.
Step 4: Select Your Data Storage Management
Decide how to store your events. Consider the following storage options based on your data requirements:
- Apache Hadoop: Suitable for large-scale batch data processing.
- Apache Cassandra: Designed for high availability and scalability with high write throughput.
- JSON on NoSQL Databases: If unstructured data will be processed frequently.
Step 5: Analytics Layer Setup
Once data is stored, employ an analytics layer. Use tools that best meet your analysis needs:
- Apache Spark: For advanced analytics and machine learning capabilities.
- Tableau and Power BI: For creating interactive dashboards and visualizations.
Step 6: Establish Real-time Monitoring and Alerting
Implement monitoring tools to keep track of system performance and event flow. Use solutions like Prometheus or Grafana to visualize metrics and set up alerts for any anomalies in the event processing pipeline.
Step 7: Data Governance and Security
Determine governance standards for data privacy and compliance. Implement security measures for data protection, including encryption and access controls. Specify policies for data retention and event lifecycle management.
Best Practices for Event-Driven Big Data Analytics
Embrace Microservices Architecture
Microservices enable you to break down your application into smaller, manageable services that can develop, deploy, and scale independently. This is ideal for handling various event types within a big data context.
Ensure Loose Coupling
Components should be designed to communicate without intimate knowledge of one another. This leads to easier maintenance and allows for independent updates.
Optimize Event Schema Management
Define a standardized event schema that ensures consistency across different data producers. Tools like Confluent Schema Registry can manage versioned schemas effectively.
Monitor Performance Continuously
Adopt a mindset focused on continuous improvements in your architecture. Regular performance assessments and load-testing exercises will help you identify bottlenecks and plan for scale.
Conclusion
By leveraging an event-driven architecture, organizations can create an agile and responsive big data analytics environment. With real-time data processing and the potential for immediate insights, businesses can adapt swiftly to changing trends and demands.
In the realm of Big Data, incorporating event-driven architecture can revolutionize analytics capabilities by enabling real-time processing and analysis of streaming data. By carefully designing and implementing a robust event-driven Big Data analytics architecture, organizations can unlock timely insights, enhance decision-making, and stay ahead in today’s data-driven landscape.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 How Elasticsearch is Used in Big Data Applications
How Elasticsearch is Used in Big Data Applications
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data