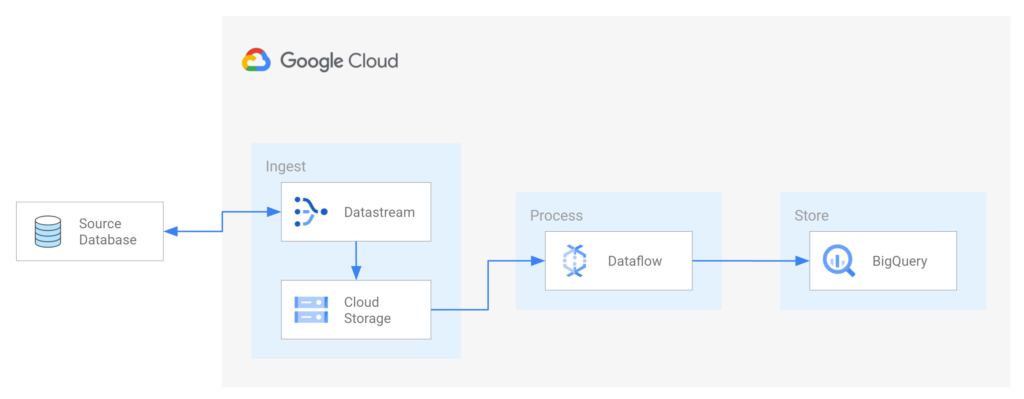
Implementing data streaming with Google Dataflow is a crucial aspect of managing and analyzing Big Data efficiently. Dataflow, a fully managed service provided by Google Cloud, allows organizations to process and analyze large volumes of data in real-time. By leveraging Dataflow, businesses can transform and enrich their data streams, enabling them to derive valuable insights quickly and make informed decisions promptly. In this article, we will explore the key considerations and steps to efficiently implement data streaming with Google Dataflow, empowering organizations to harness the power of Big Data effectively.
Data streaming is an essential aspect of modern Big Data frameworks. Google Dataflow allows organizations to process real-time data efficiently, offering a robust solution for building data-driven applications. This article will guide you through the step-by-step process of implementing data streaming with Google Dataflow, focusing on core concepts, architecture, and best practices.
Understanding Google Dataflow
Google Dataflow is a fully-managed service designed to execute a wide variety of batch and streaming data processing tasks. It is part of the Google Cloud Platform (GCP) and allows for seamless integration with other GCP products like Google Cloud Storage, BigQuery, and Cloud Pub/Sub. Dataflow leverages the Apache Beam programming model, which simplifies the development of both streaming and batch processing pipelines.
The Benefits of Using Google Dataflow
- Scalability: Automatically scales resources based on the workload.
- Unified Model: Supports both stream and batch data processing.
- Cost-Effective: Pay only for the resources you use.
- Integration: Easily integrates with various Google Cloud services.
Setting Up Your Environment
Before implementing data streaming with Google Dataflow, ensure you have set up your Google Cloud environment correctly.
1. Create a Google Cloud Project
First, create a new project in the Google Cloud Console. This project will house all your resources, including Dataflow jobs, Pub/Sub topics, and any associated storage buckets.
2. Enable Required APIs
Next, you must enable the following APIs:
- Dataflow API
- Pub/Sub API
- Cloud Storage API
Navigate to the API Library in your Google Cloud Console, search for each API, and enable them accordingly.
3. Set Up Billing
Google Cloud services are billed based on usage. Make sure you have set up a billing account for your project, which can be done under the Billing section of the Google Cloud Console.
Core Concepts of Data Streaming in Google Dataflow
Before diving into implementation, it’s important to understand some of the core concepts associated with Google Dataflow.
Streaming vs. Batch Processing
While batch processing operates on a large group of records collected over time, streaming processing deals with continuously generated data. Google Dataflow can handle both, often through the same pipeline.
Pipeline
A pipeline is a series of processing steps that define how data flows through the system and is transformed. In a streaming context, data flows constantly, allowing for instant processing.
Transformations
Transformations are operations that can be performed on data elements, such as filtering, mapping, or grouping. Google Dataflow provides several built-in transformations for both batch and streaming data.
Windowing
Windowing allows you to segment your data stream into manageable chunks for processing. This is especially useful for scenarios where you need to analyze data over specific time frames.
Implementing Data Streaming with Google Dataflow
Let’s walk through the implementation of a real-time data streaming application using Google Dataflow and Cloud Pub/Sub.
Step 1: Create a Pub/Sub Topic
Google Cloud Pub/Sub is a messaging service for exchanging data between applications. To create a Pub/Sub topic:
- Go to the Pub/Sub section in the Google Cloud Console.
- Click on Create topic.
- Name your topic (e.g., `my-streaming-topic`) and click Create.
Step 2: Set Up Google Cloud Storage
You will also need a Cloud Storage bucket to store output data. Follow these steps:
- Go to the Cloud Storage section in the Google Cloud Console.
- Click on Create bucket.
- Follow the prompts to name your bucket and ensure it is set to the appropriate storage class.
Step 3: Write Your Dataflow Pipeline
To build the Dataflow pipeline, you can use languages like Java or Python. Here’s an example using Python with Apache Beam SDK:
from apache_beam import Pipeline
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.io import ReadFromPubSub, WriteToText
# Define the pipeline options
options = PipelineOptions(
flags=None,
runner='DataflowRunner',
project='your-project-id',
temp_location='gs://your-bucket/temp/'
)
# Create the pipeline
with Pipeline(options=options) as p:
(p
| 'Read from PubSub' >> ReadFromPubSub(topic='projects/your-project-id/topics/my-streaming-topic')
| 'Transform Data' >> Map(lambda x: process_data(x)) # Replace with your transformation logic
| 'Write to Google Cloud Storage' >> WriteToText('gs://your-bucket/output/results'))
Replace `process_data(x)` with your data processing function.
Step 4: Deploy Your Pipeline
To deploy your pipeline, you can use the command line interface or the Google Cloud Console:
- Make sure you have the Google Cloud SDK installed and authenticated.
- Run the following command:
python your_pipeline.py --project your-project-id --runner DataflowRunner --temp_location gs://your-bucket/temp/Step 5: Monitor Your Dataflow Job
Once your pipeline is up and running, you can monitor its performance through the Google Cloud Console under the Dataflow section. Here, you will be able to see job status, execution details, and logs.
Best Practices for Data Streaming with Google Dataflow
- Efficient Windowing: Use windowing wisely to prevent excessive memory consumption.
- Auto-scaling: Take advantage of Dataflow’s auto-scaling to manage resources effectively.
- Monitoring: Set up logging and monitoring to quickly identify issues in your streaming data pipeline.
- Testing: Test your pipeline rigorously using different datasets to ensure it handles real-world scenarios.
Conclusion
Implementing data streaming with Google Dataflow provides organizations with a powerful tool to process and analyze data in real-time. By following this guide on setup, development, deployment, and best practices, businesses can leverage the full potential of their data in today’s fast-paced digital environment.
Implementing data streaming with Google Dataflow in the context of Big Data offers a powerful solution for real-time data processing and analysis. By harnessing the scalability and flexibility of this platform, organizations can efficiently manage and analyze large volumes of data, enabling them to make timely and informed decisions to drive business success.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI