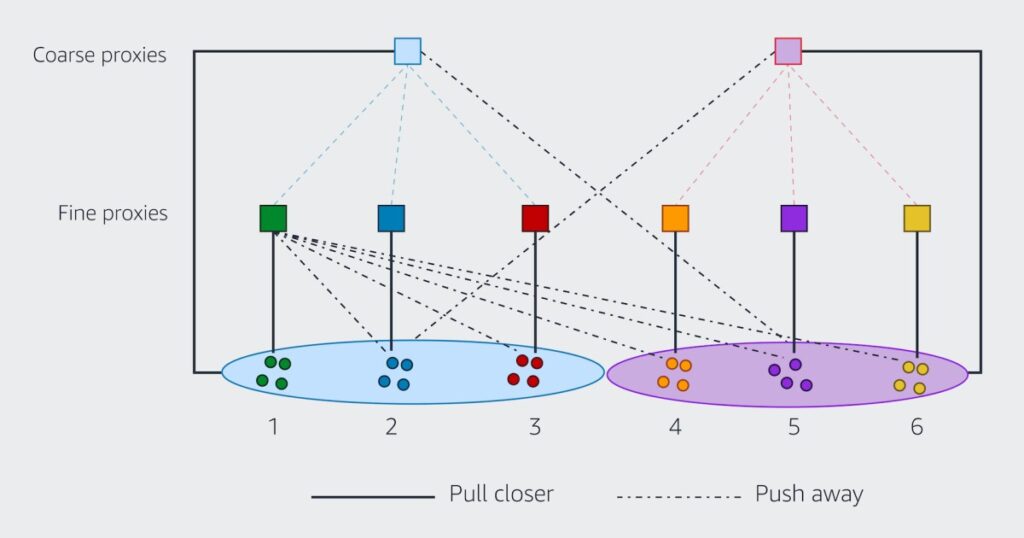
Hierarchical representation learning is a powerful technique in the field of Big Data analytics that involves organizing data into multiple layers of abstraction to capture complex relationships and patterns. Implementing hierarchical representation learning on Big Data requires a combination of advanced machine learning algorithms, scalable computing infrastructure, and careful data preprocessing. In this approach, data is transformed into hierarchical structures, enabling deep learning models to extract increasingly abstract features from the raw data. This method can significantly enhance the accuracy and efficiency of data analysis tasks, making it a valuable tool for uncovering insights from large and complex datasets in the era of Big Data.
Understanding Hierarchical Representation Learning
Hierarchical Representation Learning (HRL) is a powerful approach that allows models to capture complexity in data by organizing it into multiple levels of abstraction. This technique is particularly beneficial for Big Data as traditional methods often struggle to handle the vast intricacies present in large datasets. HRL enables better feature extraction, facilitates enhanced predictive modeling, and improves overall performance in machine learning tasks.
Key Concepts in Hierarchical Representation Learning
To effectively implement Hierarchical Representation Learning, it’s crucial to understand core concepts:
- Representation Learning: This is a type of machine learning that focuses on discovering the underlying structure of data. It helps in transforming raw data into useful features.
- Hierarchical Structures: HRL leverages the hierarchical organization of data, which allows models to learn features at various levels, from low-level elements to high-level abstractions.
- Dimensionality Reduction: In big datasets, dimensionality reduction techniques like PCA (Principal Component Analysis) can be integrated into the HRL framework to streamline processing capabilities.
Steps to Implement Hierarchical Representation Learning on Big Data
1. Data Collection and Preprocessing
Effective implementation starts with robust data collection. You must gather large volumes of data from diverse sources, including:
- Databases: SQL and NoSQL databases like MySQL, MongoDB, and Cassandra.
- APIs: Accessing data through RESTful APIs that return large datasets.
- Logs and Streaming Data: Using tools like Apache Kafka for real-time data ingestion.
Once the data is collected, preprocessing is vital. This step includes:
- Data Cleaning: Addressing issues like missing values, duplicate records, and irrelevant data.
- Normalization: Scaling the data to ensure consistent unit representation, especially for features with differing ranges.
- Feature Selection: Identifying and retaining significant features while eliminating noisy ones.
2. Building the Hierarchical Structure
In Hierarchical Representation Learning, organizing your data into a hierarchy is fundamental. Typically, a tree-like structure is ideal for this purpose:
- Define Levels: Start by determining the different levels of hierarchy based on the significance of features. For instance, in a text dataset, you could have levels for document, paragraph, sentence, and word.
- Tree Construction: Implement a tree structure using libraries such as SciPy or NetworkX in Python to visualize relationships and extract features across different levels.
3. Selecting the Right Algorithms
Choosing effective algorithms is crucial for successful HRL implementation. Here are several algorithms that work well with big data:
- Deep Learning Models: Utilize deep neural networks (DNNs) or convolutional neural networks (CNNs) for feature extraction that automatically learns hierarchical patterns.
- Tree-based Models: Algorithms such as Random Forests or Gradient Boosting Machines can be utilized in conjunction with decision trees to capture hierarchical relationships.
- Autoencoders: These are especially useful for unsupervised representation learning, where the goal is to compress the input into lower-dimensional space and then reconstruct it. Variational Autoencoders (VAEs) can also be applied for probabilistic representation learning.
4. Integration of Dimensionality Reduction Techniques
With large datasets, dimensionality reduction can significantly enhance HRL performance. Techniques to consider include:
- Principal Component Analysis (PCA): This identifies key features that contribute to the variance in the dataset while reducing dimensionality.
- T-distributed Stochastic Neighbor Embedding (t-SNE): Useful for visualizing high-dimensional data by maintaining local relationships.
- Uniform Manifold Approximation and Projection (UMAP): This approach offers non-linear dimensionality reduction while preserving the topological structure.
5. Training the Model
Once you have set up the structure, selected algorithms, and reduced dimensionality, the next step is training the model:
- Split the Data: Divide the data into training, validation, and test sets to evaluate the model’s performance accurately.
- Optimization: Use techniques like gradient descent, Adam optimizer, or RMSprop to enhance training convergence and minimize loss functions.
- Regularization: To prevent overfitting, consider methods like L1 or L2 regularization, dropout layers, or early stopping.
6. Model Evaluation and Hyperparameter Tuning
After training, evaluating the model’s performance is critical. You can use metrics such as:
- Accuracy: The proportion of true results among the total number of cases examined.
- Precision and Recall: These metrics are particularly useful in classification tasks.
- F1 Score: The harmonic mean of precision and recall, providing a balance between the two.
- AUC-ROC Curve: This metric assesses the ability of the model to distinguish between classes.
Hyperparameter tuning can further improve performance. Techniques such as Grid Search or Random Search can help identify the best parameters for your model.
7. Deployment and Scalability
Once the model is trained and evaluated, it’s time to deploy it:
- Model Serving: Use platforms like TensorFlow Serving or AWS SageMaker to deploy your model, making it accessible for prediction.
- Monitor Performance: Continuously monitor the model to ensure optimal performance and adjust for changes in data over time.
- Scaling: Consider containerization with Docker or orchestration with Kubernetes to manage scaling and resource allocation effectively.
8. Real-World Applications of Hierarchical Representation Learning on Big Data
Hierarchical Representation Learning has numerous applications in Big Data contexts, including:
- Natural Language Processing (NLP): Used in sentiment analysis, topic modeling, and machine translation, HRL can help extract multi-level insights from textual data.
- Image Recognition: In computer vision, hierarchical features help in identifying objects and their relationships within an image.
- Recommendation Systems: HRL can improve user profiling and item similarity measures, enhancing the personalization of recommendations.
- Health Analytics: Medical data can be processed using HRL for enhanced patient diagnosis and outcome prediction based on various hierarchical features.
Conclusion
Implementing Hierarchical Representation Learning on Big Data is a multifaceted process that integrates data collection, model building, evaluation, and deployment. By leveraging hierarchical structures and sophisticated algorithms, organizations can uncover deep insights and drive value from their large datasets.
Implementing hierarchical representation learning on Big Data presents an effective method to unlock valuable insights from complex and massive datasets. By leveraging hierarchical structures and deep learning techniques, organizations can improve the scalability, efficiency, and accuracy of their data processing and analysis processes, leading to better decision-making and innovation. As the volume and complexity of Big Data continue to grow, adopting hierarchical representation learning is crucial for maximizing the potential of these vast datasets in various industries and applications.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 The Evolution of Big Data Technologies: Past, Present, and Future
The Evolution of Big Data Technologies: Past, Present, and Future
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics