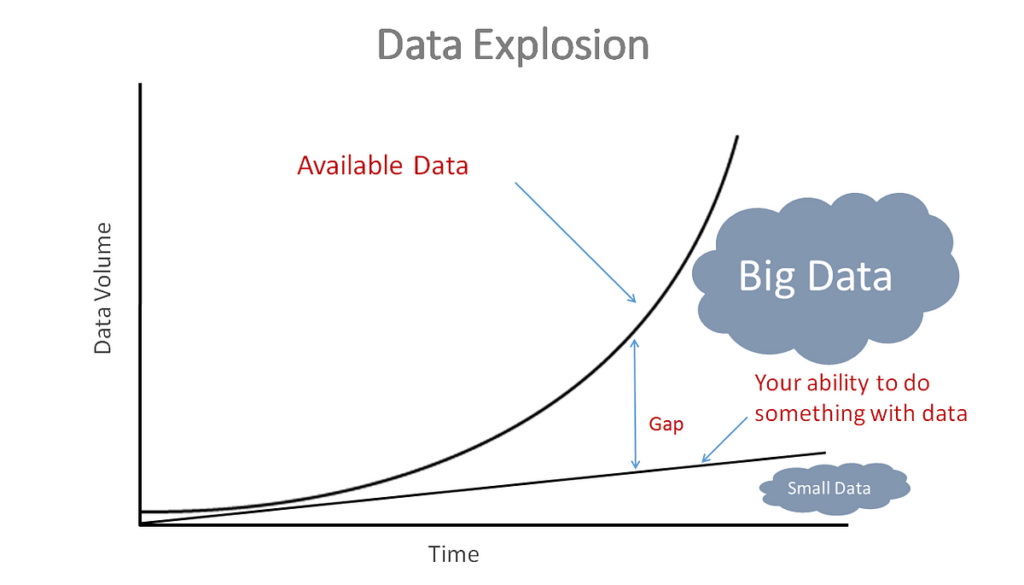
Implementing out-of-core learning on large Big Data datasets is crucial for maximizing the efficiency of machine learning algorithms when dealing with massive amounts of data that cannot fit into memory all at once. By utilizing out-of-core techniques, such as streaming data from disk, partitioning data into manageable chunks, and processing data in a sequential manner, it becomes possible to train models on datasets that exceed the memory capacity of a single machine. In this article, we will explore the principles of out-of-core learning and provide insights on how to effectively implement this approach to handle large Big Data sets in the realm of machine learning.
As the size of Big Data continues to grow exponentially, traditional in-memory data processing techniques are becoming inadequate. Out-of-core learning has emerged as a powerful solution to handle the analysis of large datasets that cannot fit into memory. This article will cover methods and practical guidelines for implementing out-of-core learning effectively.
Understanding Out-of-Core Learning
Out-of-core learning refers to techniques and algorithms designed to handle datasets that exceed the available memory of a machine. By utilizing efficient data streaming and incremental learning approaches, models can be trained on data chunks or batches without needing to load everything into memory.
Key Concepts of Out-of-Core Learning
Understanding the fundamentals of out-of-core learning is essential for implementing these techniques efficiently:
- Streaming Data: Data is processed in small sizes (or streams) rather than all at once, which minimizes memory usage.
- Incremental Learning: Models can be updated continually as new data arrives without being retrained from scratch.
- Batch Processing: Data is divided into manageable batches, allowing for gradual analysis.
Step-by-Step Guide to Implementing Out-of-Core Learning
Step 1: Choose the Right Framework
When dealing with out-of-core learning, selecting an appropriate framework is crucial. Libraries such as:
- Scikit-learn: Provides several out-of-core learning algorithms suitable for various model types.
- Dask: A parallel computing library that can handle larger-than-memory datasets.
- Apache Spark: A distributed computing framework ideal for scaling out-of-core learning across clusters.
Each framework has distinct advantages, so choose based on scalability needs and the nature of your dataset.
Step 2: Prepare Your Data
Data preprocessing is critical before implementing out-of-core learning. Follow these practices:
- Data Cleaning: Ensure your dataset is free from inconsistencies and inaccuracies by properly cleaning it.
- Data Normalization: Scale numerical features to a standard range to improve model training.
- Feature Selection: Choose relevant features to reduce dimensionality and enhance processing speed.
Step 3: Load Data in Chunks
To implement out-of-core learning effectively, data should be loaded in manageable chunks. This can be achieved using:
- Streaming APIs: Use libraries like Pandas or PySpark that allow loading and processing of data streams.
- Batch Processing: Load a fixed number of rows into memory at a time, process them, and release memory before loading the next batch.
Step 4: Implement Incremental Learning Algorithms
Only certain algorithms support incremental learning, making this step crucial. Options include:
- Stochastic Gradient Descent (SGD): Particularly well-suited for large datasets, allowing for continuous updates.
- Incremental PCA: Useful for dimensionality reduction over large datasets.
- Online Decision Trees: Trees that can be built dynamically as data is streamed.
Choosing the right algorithm depends on the characteristics of your data and the problem you are solving.
Step 5: Monitor Model Performance
During out-of-core training, it’s essential to keep an eye on your model’s performance. Techniques for monitoring include:
- Cross-Validation: Use techniques like k-folds to validate model accuracy during incremental updates.
- Metrics Tracking: Maintain performance metrics such as accuracy, precision, and recall to assess the model periodically.
Step 6: Optimize Memory Usage
Memory management is vital when working with out-of-core learning. Consider the following strategies:
- Garbage Collection: Regularly manage memory cleanup to free resources that are no longer in use.
- Data Types Optimization: Use more memory-efficient data types to reduce the overall memory foot print of datasets.
- Offloading to Disk: Utilize disk storage solutions to temporarily offload data that cannot fit into memory.
Common Challenges and Solutions
Challenge 1: Data Imbalance
Large datasets often suffer from class imbalance, which can impact training performance. Solutions include:
- Resampling Methods: Use techniques like oversampling minority class instances or undersampling the majority class.
- Cost-sensitive Learning: Apply algorithms that adjust weights based on class distribution.
Challenge 2: Model Overfitting
Overfitting is a common issue with large datasets. Mitigation techniques include:
- Regularization: Techniques like L1 and L2 regularization help prevent overfitting.
- Early Stopping: Monitor performance on a validation set to halt training when improvement ceases.
Challenge 3: Long Training Times
Processing large datasets can often lead to extended training times. To counteract this, consider:
- Distributed Learning: Use frameworks like Spark to distribute workloads across multiple machines.
- Efficient Data Loading: Ensure that data loading processes are optimized to minimize I/O bottlenecks.
Case Study: Out-of-Core Learning with Scikit-learn
Here is a practical example using the Scikit-learn library:
from sklearn.linear_model import SGDClassifier
import numpy as np
import pandas as pd
# Simulating a data streaming process
def load_data_in_chunks(file_path, chunk_size):
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
yield chunk
model = SGDClassifier()
for data_chunk in load_data_in_chunks('large_dataset.csv', chunk_size=1000):
X = data_chunk.iloc[:, :-1] # Features
y = data_chunk.iloc[:, -1] # Target Variable
model.partial_fit(X, y, classes=np.unique(y))
This code showcases how to load a large CSV file in small chunks and utilize the partial_fit() method to train an SGDClassifier incrementally.
Conclusion: Future of Out-of-Core Learning
As the volume of data continues to soar in the Big Data ecosystem, the demand for effective out-of-core learning techniques will increase. By following the outlined strategies and being aware of challenges, organizations can implement scalable, efficient models capable of handling the challenges posed by large datasets.
Implementing out-of-core learning on large Big Data datasets is crucial for efficiently processing and analyzing vast amounts of data that exceed the limits of available memory. By incorporating techniques such as data partitioning, streaming algorithms, and smart caching mechanisms, organizations can effectively handle and derive insights from massive datasets without being constrained by memory limitations. This approach not only enables scalable machine learning models but also optimizes performance and minimizes resource usage, making it a valuable solution for tackling Big Data challenges.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 How Elasticsearch is Used in Big Data Applications
How Elasticsearch is Used in Big Data Applications