Graph-based machine learning is a powerful approach to analyzing large-scale data in the realm of Big Data. By representing data in the form of interconnected nodes and edges, graph-based machine learning algorithms can extract valuable insights and patterns that may be hidden in complex datasets. Leveraging graph-based machine learning techniques enables organizations to uncover relationships, detect anomalies, make predictions, and optimize decision-making processes. In this article, we will explore how graph-based machine learning can be effectively utilized for large-scale data analysis in the context of Big Data, showcasing its potential to drive innovation and unlock actionable intelligence from massive datasets.
Understanding Graph-Based Machine Learning
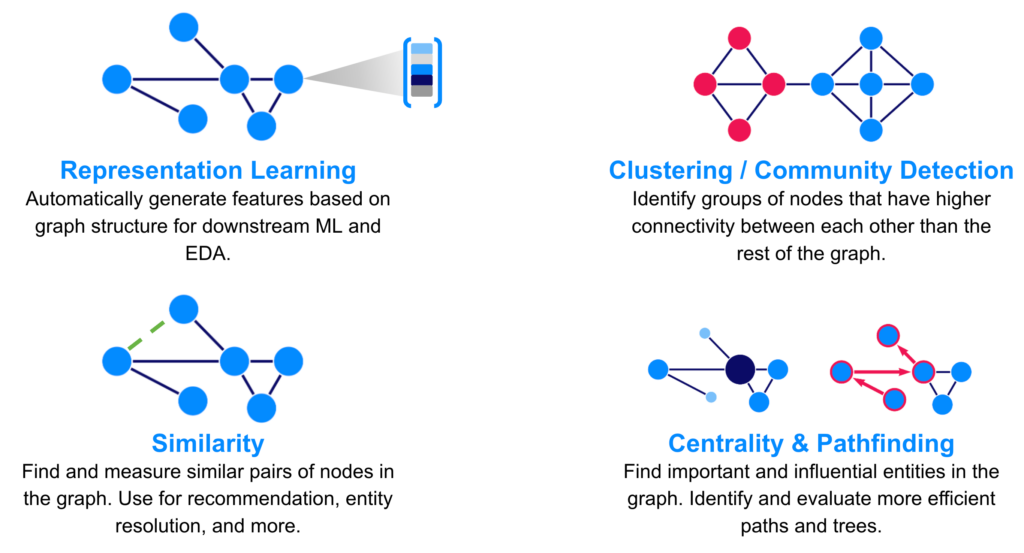
Graph-based machine learning is an innovative approach that utilizes the structure of graphs to analyze and extract insights from complex datasets. Unlike traditional machine learning methods, which often treat data as independent and identically distributed (i.i.d), graph-based approaches recognize the interconnections between entities. This method is particularly powerful when dealing with large-scale data where relationships and interactions are as important as the data points themselves.
The Importance of Graphs in Big Data
In the world of Big Data, data is often interconnected. Social networks, biochemical networks, and transportation systems are examples where data points are not isolated; instead, they interact and relate to each other in intricate ways. Utilizing graphs allows for:
- Enhanced Modeling – Graphs can effectively model relationships and dependencies among entities, leading to more accurate predictions.
- Efficient Data Representation – Graph structures simplify complex relationships, making it easier to query and analyze vast datasets.
- Scalability – Graph-based algorithms, such as those implemented with frameworks like Apache Spark, can scale to handle billions of nodes and edges.
Key Techniques in Graph-Based Machine Learning
Several fundamental techniques in graph-based machine learning can significantly improve large-scale data analysis. Here are some notable ones:
1. Node Classification
Node classification is the task of predicting the category of a node within a graph. For instance, in a social network, one might predict whether a user is active or inactive based on their connections and interactions. Techniques for node classification include:
- Graph Convolutional Networks (GCNs) – These networks aggregate features from a node’s neighbors to enhance the understanding of node characteristics.
- Label Propagation – This semi-supervised learning technique propagates labels through the network to classify unlabeled nodes based on their connections.
2. Link Prediction
Link prediction focuses on determining the likelihood of a link existing between two nodes. This is particularly useful in recommendation systems, where, for example, we can suggest new friends on a social platform or items for purchase based on a user’s preferences and their network. Algorithms for link prediction include:
- Matrix Factorization – This linear algebra technique decomposes the adjacency matrix of the graph to predict missing links.
- Graph Neural Networks (GNNs) – These networks can learn the latent representations of nodes, making them efficient for link prediction tasks.
3. Community Detection
Community detection identifies distinct groups or clusters within a graph. This can help businesses understand customer segments or researchers find subfields within a scientific domain. Popular algorithms used for this task include:
- Louvain Method – This method optimizes modularity to discover community structures.
- Girvan-Newman Algorithm – This algorithm recursively removes edges to detect communities based on the betweenness centrality of edges.
Implementing Graph-Based Machine Learning
Here is a step-by-step guide on how to implement graph-based machine learning for large-scale data analysis:
Step 1: Data Collection
The initial step involves gathering data from various sources. This can include social media, transaction logs, sensors, or any environment where data is interrelated. Ensure that the data captures both the attributes of the entities and the relationships between them.
Step 2: Data Preparation
Once the data is collected, it’s essential to prepare it for analysis. This involves cleaning the data, removing duplicates, and handling missing values. Additionally, extract relevant features from the data that will be useful in modeling the graph.
Step 3: Constructing the Graph
With prepared data, the next step is constructing the graph. Nodes represent entities, while edges represent the relationships. Choose appropriate data structures to represent large graphs efficiently. Frameworks like Neo4j or graph databases like Amazon Neptune can support this step.
Step 4: Applying Graph Algorithms
Utilize various graph algorithms based on your analysis objectives. Depending on whether you’re focusing on node classification, link prediction, or community detection, implement the corresponding algorithms. Use libraries such as PyTorch Geometric or DGL (Deep Graph Library), which provide robust tools for graph neural networks.
Step 5: Model Evaluation
After applying the graph algorithms, evaluate the models to determine their performance. Common metrics for evaluation include precision, recall, and F1 score. For link prediction, the area under the ROC curve is often used. Fine-tune your models based on the results.
Step 6: Deploying the Model
Once satisfied with the model’s performance, deploy it using cloud services for scalability and monitoring. Consider incorporating streaming data to ensure real-time analysis, adjusting the model as more data flows in.
Challenges of Using Graph-Based Machine Learning
While graph-based machine learning offers benefits, it also presents challenges, especially with large-scale data:
- Computational Complexity – The computational overhead can increase significantly, making it difficult to scale. Optimization techniques and distributed computing solutions can help mitigate this.
- Data Sparsity – Graphs can be sparse, meaning many node pairs do not have direct edges. Addressing this can require advanced techniques like embedding or using neighborhood sampling.
- Quality of Graph Data – Ensuring the quality of the data used to construct the graph is crucial. Poor quality data can lead to misleading results.
The Future of Graph-Based Machine Learning
The future of graph-based machine learning is promising, particularly with the ongoing advancement of Artificial Intelligence and data science. As organizations continue to grapple with massive amounts of data, understanding underlying relationships becomes more critical. Expected trends include:
- Integration with Deep Learning – Graph neural networks combining principles from deep learning are likely to provide superior insights.
- Real-Time Data Processing – Streaming data analysis will allow businesses to make quicker decisions based on real-time interactions.
- Cross-Domain Applications – Graph-based techniques will likely expand across various industries, including healthcare, finance, and logistics, to derive relevant insights from interconnected data.
Conclusion
In summary, leveraging graph-based machine learning for large-scale data analysis presents an opportunity for businesses to harness relationships within their datasets effectively. By implementing these advanced techniques, organizations can enhance their data insights, improve decision-making, and stay ahead in an increasingly complex data landscape.
Leveraging graph-based machine learning for large-scale data analysis in the realm of Big Data offers a powerful and efficient approach to uncovering complex patterns and insights within interconnected datasets. By harnessing the inherent relationships and structures present in graphs, organizations can enhance their decision-making processes, optimize performance, and drive innovation in diverse industries. Embracing this cutting-edge technology opens up a world of possibilities for unlocking valuable knowledge from vast and dynamic datasets, paving the way for data-driven success in the era of Big Data.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data