Optimizing distributed joins in Big Data queries is critical for ensuring efficient query processing and timely retrieval of information in large-scale data environments. With the ever-increasing volume, velocity, and variety of data being generated, it’s essential to employ strategies that enhance the performance of distributed join operations. By leveraging parallel processing, partitioning, indexing, and applying optimal join algorithms, organizations can significantly improve the speed and scalability of their Big Data queries. This article delves into key techniques and best practices to optimize distributed joins in Big Data queries to maximize the efficiency of data processing and analysis in modern data-driven environments.
Understanding Distributed Joins in Big Data
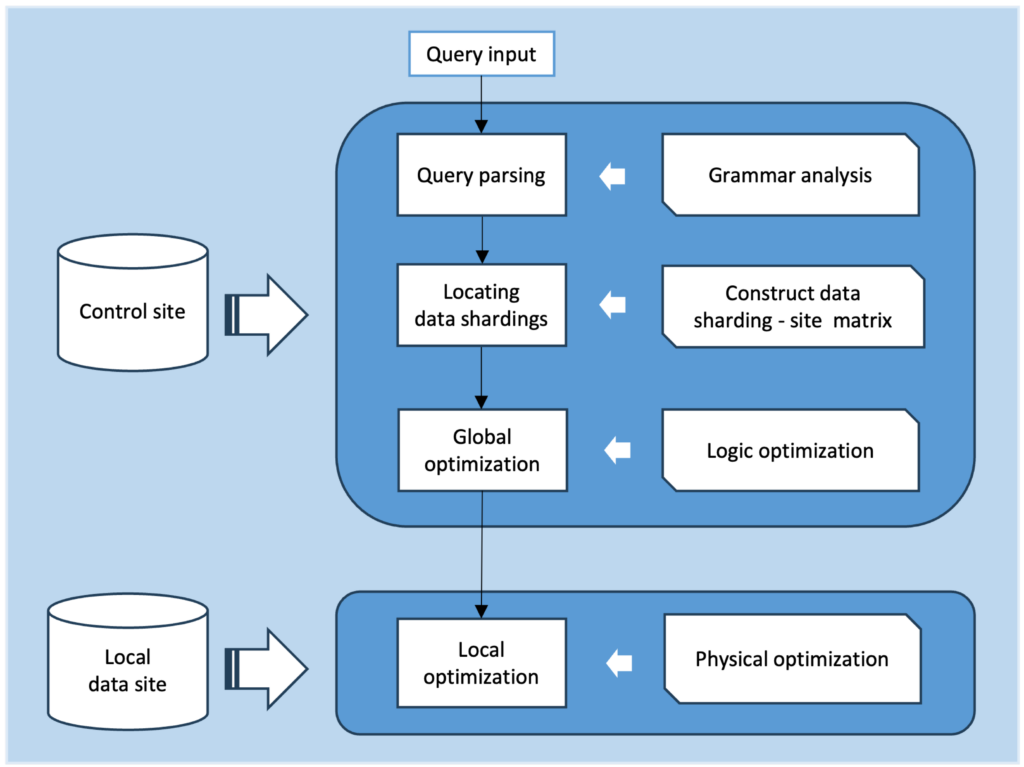
In big data environments, data is often stored across multiple nodes, requiring sophisticated techniques to perform efficient queries. A distributed join combines rows from two or more tables based on related columns, and when executed improperly, can lead to performance bottlenecks.
Common Challenges with Distributed Joins
Distributed joins come with several challenges, including:
- Data Skew: Uneven distribution of data can lead to some nodes being overloaded.
- Network Latency: Data transfer between nodes can slow down the process significantly.
- Memory Limits: Large data sets can exceed the memory capacity of the processing nodes.
Best Practices for Optimizing Distributed Joins
1. Use Broadcast Joins for Small Datasets
When one of the tables in a join operation is small enough to fit into memory, consider using a broadcast join. This technique involves sending the smaller dataset to all nodes, allowing for local joins instead of distributing the larger dataset.
2. Filter Data Early
Apply filtering conditions as early as possible in your query to reduce the data volume that needs to be joined. The less data you need to process, the faster the join will execute.
3. Optimize Join Order
The order of tables in a join can significantly impact performance. Analyze the size of tables and the expected output to determine the best join sequence. Joining smaller tables first can reduce the dataset size in subsequent joins.
4. Partitioning and Bucketing
Proper data partitioning and bucketing strategies can improve join performance by colocating data that is frequently accessed together. In partitioning, tables are divided into parts based on a key, while bucketing divides them further into files within the partition.
5. Utilize Efficient Join Algorithms
Familiarize yourself with different join algorithms available in your big data processing engine. Common algorithms include:
- Map-Side Joins: Used when one table is much smaller than the other.
- Sort-Merge Joins: Efficient for larger datasets but requires sorting.
- Shuffle Hash Joins: Useful when both datasets are large and need to be redistributed.
6. Leverage Indexing and Caching
Indexing can speed up query execution times, especially for frequently joined columns. Implementing caching for commonly accessed datasets can also reduce retrieval times for repeat queries.
7. Consider Data Locality
Data locality refers to processing data where it resides, minimizing data movement. Adapt your data architecture to take data locality into account, which will enhance overall join performance.
Advanced Techniques for Distributed Joins
1. Adaptive Query Execution
Many modern big data frameworks provide features for adaptive query execution. This allows the system to modify the execution plan based on the runtime statistics of data, optimizing joins by taking actual data distribution into account.
2. Using Materialized Views
Materialized views can be precomputed and stored, improving access times for complex joins that are frequently utilized. Consider creating materialized views for often-used queries to enhance performance.
3. Incremental Processing
Instead of performing full joins every time, use incremental processing techniques to update only the changed data. This is particularly useful in streaming data scenarios where frequent updates occur.
4. External Tool Integration
Integrate external tools like Apache Spark or Presto that offer optimized execution engines for distributed joins. These tools provide advanced query optimization features and can better utilize cluster resources.
Measuring and Monitoring Join Performance
To effectively optimize distributed joins, it is essential to measure their performance continuously. Consider the following approaches:
1. Track Query Execution Time
Monitor the execution time of your join queries to identify lengthy processes. Document query performance over time and optimize based on observed results.
2. Analyze Resource Utilization
Assess CPU and memory utilization during join operations. This information can help determine bottlenecks and areas for improvement in hardware or query structure.
3. Log Queries for Performance Review
Maintain logs for your queries to review past performance metrics. By analyzing these logs, you can identify patterns, clusters, or common failures during join operations.
Tools and Technologies for Optimizing Distributed Joins
In the ever-evolving landscape of big data, various tools can assist in optimizing distributed joins:
- Apache Hive: Provides SQL-like capabilities on top of Hadoop, allowing for efficient joins.
- Apache Spark: Offers in-memory processing and optimization for large-scale data processing.
- Presto: An open-source distributed SQL query engine designed for running interactive analytic queries.
- Amazon Athena: Serverless and can be employed for running queries on large datasets in Amazon S3.
Conclusion
Optimizing distributed joins is crucial for improving the performance of big data queries. By implementing the best practices and advanced techniques discussed in this article, data engineers can significantly enhance query efficiency, reduce execution time, and ultimately drive better business outcomes. Remember, the goal is not just to execute joins but to do so with a level of speed and efficiency that meets today’s data demands.
Optimizing distributed joins in Big Data queries is essential for improving performance and efficiency in processing large and complex datasets. By considering factors such as data distribution, partitioning strategies, and parallel processing techniques, organizations can reduce latency and maximize resource utilization in their Big Data operations. Implementing effective optimization strategies will ultimately lead to faster query execution times and enhanced scalability for handling massive amounts of data in distributed environments.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem