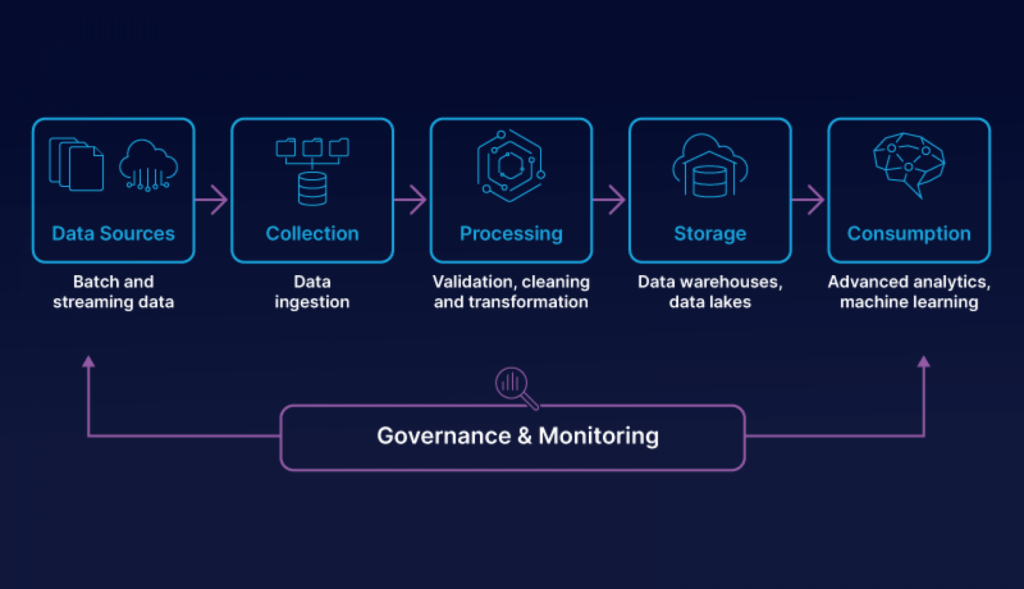
In the realm of Big Data processing, ensuring data quality is crucial for maintaining the accuracy, reliability, and efficiency of data pipelines. Automated data quality checks play a vital role in this process by allowing organizations to identify and resolve data issues in real-time, thereby minimizing the risk of making erroneous business decisions based on flawed data. In this article, we will explore the importance of performing automated data quality checks in Big Data pipelines and discuss practical strategies for implementing these checks effectively.
Understanding the Importance of Data Quality in Big Data
Data quality is paramount in any Big Data environment. High-quality data is essential for accurate analytics, effective decision-making, and overall business success. Data that is incomplete, inaccurate, or inconsistent can lead to faulty insights and severely hinder operational efficiency. As organizations strive to manage large datasets, it becomes increasingly critical to implement rigorous data quality checks throughout the data pipeline.
Automated data quality checks utilize technologies and frameworks to ensure that data meets certain standards before it is analyzed or processed further. By integrating these checks into your Big Data pipelines, you can significantly enhance the reliability of your data.
Common Data Quality Issues
Before diving into automated checks, it’s crucial to recognize common data quality issues that can arise:
- Incompleteness: Missing values or records in datasets that can distort analysis.
- Inaccuracy: Incorrect data entries that lead to misguided conclusions.
- Inconsistency: Data that varies across datasets, reducing trustworthiness.
- Duplication: Redundant records that can skew results.
- Outdated Information: Data that is no longer relevant or useful.
Frameworks and Tools for Automated Data Quality Checks
Several frameworks and tools have emerged to facilitate automated data quality checks in Big Data pipelines. Below are some popular choices:
Apache Griffin
Apache Griffin is an open-source data quality solution designed for Big Data. It seamlessly integrates with various data processing frameworks like Hadoop, Spark, and more. Griffin allows you to define data quality metrics, enabling organizations to enforce a consistent data quality strategy through automated checks.
Great Expectations
Great Expectations is a powerful tool for creating, documenting, and testing data quality. Its built-in expectations framework helps users define what “good” data looks like and automatically checks for deviations from these standards. Great Expectations can also integrate with various data storage options and visualization tools, making it a flexible choice for any data pipeline.
Apache Deequ
Apache Deequ is another open-source tool crafted specifically for data validation in Apache Spark. Using Declarative Data Quality, Deequ allows you to define data quality constraints through a programming approach, automating the quality checks during the data processing phase.
Best Practices for Implementing Automated Data Quality Checks
To ensure the effectiveness of your automated data quality checks, here are some best practices to consider:
1. Define Clear Quality Metrics
Establishing clear metrics is essential for assessing data quality. These metrics should be based on business requirements and may include:
- Completeness
- Uniqueness
- Timeliness
- Consistency
- Validity
2. Integrate Checks at Different Pipeline Stages
Automated data quality checks should occur at multiple stages of the data pipeline:
- Data Ingestion: Validate incoming data for structure and format.
- Data Transformation: Ensure the data retains quality through transformations.
- Data Storage: Check the integrity of the stored data.
- Data Distribution: Verify that the data is consistent across various platforms and users.
3. Use Machine Learning for Anomaly Detection
Employ machine learning algorithms to identify anomalies and deviations in data quality. Techniques like clustering and classification can help guide your checks, making them more precise and context-aware.
4. Enable Alerts and Reporting
Automate alerts to notify data engineers and stakeholders of any data quality issues. Comprehensive reporting on data quality checks not only enhances transparency but also facilitates data-driven conversations about data improvement strategies.
5. Continuous Improvement
Data quality is not a one-time task but requires continuous improvement. Review your automated checks periodically based on feedback and evolving business requirements. Regular audits and adjusting your metrics will ensure that you’re always aligned with business needs.
Steps to Set Up Automated Data Quality Checks
Follow these steps to set up your automated data quality checks:
Step 1: Identify Key Data Sources
Begin by identifying the critical data sources that feed into your Big Data pipeline. This could include databases, cloud storage, and real-time streams.
Step 2: Determine Data Quality Requirements
Gather stakeholders to understand their data quality needs. Document the specific quality requirements for each data source and process.
Step 3: Select the Right Tool
Based on your data quality requirements and the existing data ecosystem, choose the appropriate tool (Apache Griffin, Great Expectations, Apache Deequ, etc.) that aligns with your pipeline.
Step 4: Design Quality Checks
Design and implement the necessary automated checks based on your previously defined data quality metrics. Ensure these checks are scalable and can adapt to data growth.
Step 5: Test Your Quality Checks
Before deploying, rigorously test your automated checks in a staging environment. Simulate various data scenarios to verify that checks respond accurately to data quality issues.
Step 6: Monitor and Adjust
After deployment, continuously monitor the performance of your automated data quality checks. Solicit feedback from users and adjust thresholds, notifications, or metrics as necessary to maintain data integrity.
Key Takeaways on Automated Data Quality Checks
Automated data quality checks are crucial in Big Data pipelines to ensure that organizations can trust their data for decision-making. By leveraging tools such as Apache Griffin, Great Expectations, and Apache Deequ, organizations can design a robust data quality strategy.
Establishing clear metrics, integrating checks at various stages, using machine learning for anomaly detection, enabling alerts, and continuously improving the process is key to effective management of data quality in your Big Data ecosystem.
Implementing automated data quality checks in Big Data pipelines is essential to ensure the reliability and integrity of data processed at scale. By utilizing advanced tools and techniques, organizations can proactively identify and address inconsistencies, anomalies, and errors in real-time, enabling better decision-making and maximizing the value of Big Data analytics. This not only enhances the overall data quality but also helps in improving efficiency and reducing the risk of making critical business decisions based on flawed data.
Related posts:
 The Future of Digital Twins in Large-Scale Big Data Simulations
The Future of Digital Twins in Large-Scale Big Data Simulations
 The Impact of Federated Analytics on Big Data Privacy
The Impact of Federated Analytics on Big Data Privacy
 The Role of Causal AI in Understanding Big Data Relationships
The Role of Causal AI in Understanding Big Data Relationships
 How to Perform Large-Scale Time Series Forecasting with Big Data
How to Perform Large-Scale Time Series Forecasting with Big Data
 The Role of AutoML in Scaling Big Data Model Deployment
The Role of AutoML in Scaling Big Data Model Deployment
 How to Optimize Storage Formats for Big Data Performance
How to Optimize Storage Formats for Big Data Performance
 The Importance of Event Sourcing in Big Data Architecture
The Importance of Event Sourcing in Big Data Architecture
 How to Perform Real-Time Outlier Detection in Big Data Pipelines
How to Perform Real-Time Outlier Detection in Big Data Pipelines
 The Future of AI-Powered Data Wrangling for Big Data Scientists
The Future of AI-Powered Data Wrangling for Big Data Scientists
 The Role of Synthetic Tabular Data Generation in Big Data Training Sets
The Role of Synthetic Tabular Data Generation in Big Data Training Sets
 The Future of Hypergraph-Based Machine Learning in Big Data Applications
The Future of Hypergraph-Based Machine Learning in Big Data Applications
 How to Use Apache SeaTunnel for ETL in Big Data Pipelines
How to Use Apache SeaTunnel for ETL in Big Data Pipelines
 The Role of AI in Automated Feature Selection for Big Data Models
The Role of AI in Automated Feature Selection for Big Data Models