Performing Bayesian inference on large Big Data datasets is a complex and challenging task due to the sheer volume and complexity of the data involved. Bayesian inference allows us to update our beliefs about a hypothesis or model based on new evidence or data. In the realm of Big Data, traditional computational methods may not be sufficient to handle the vast amount of information available. In this context, specialized techniques and algorithms tailored for Big Data environments are essential to effectively conduct Bayesian inference. This article will explore the unique considerations and strategies for performing Bayesian inference on large Big Data datasets, highlighting the importance of scalability, computational efficiency, and accuracy in leveraging the power of Big Data for Bayesian analysis.
Bayesian inference is an essential statistical method that allows researchers to draw conclusions about data by updating beliefs in light of new evidence. It is particularly powerful when applied to big data because it can combine prior information with observed data to enhance the decision-making process. This article will delve into the steps, techniques, and tools required to effectively perform Bayesian inference on large datasets.
Understanding Bayesian Inference
Before diving into the methodology, it is crucial to understand the fundamental concepts of Bayesian inference. Bayesian inference relies on Bayes’ theorem, which relates the conditional and marginal probabilities of random variables. The theorem can be expressed as:
P(H|E) = (P(E|H) * P(H)) / P(E)
Where:
- P(H|E) is the posterior probability of the hypothesis H given evidence E.
- P(E|H) is the likelihood of the evidence E given that H is true.
- P(H) is the prior probability of the hypothesis H before observing the evidence.
- P(E) is the marginal probability of the evidence E.
The beauty of Bayesian inference is in the iterative updating of probabilities as new data becomes available, making it particularly suited for large big data datasets.
Challenges of Performing Bayesian Inference on Big Data
There are numerous challenges associated with applying Bayesian inference to big data:
- Scalability: Traditional Bayesian methods can be computationally intensive, leading to performance issues as data size increases.
- Complexity: Complex models may require significant computational resources to estimate.
- Data Quality: Big datasets often contain noise and outliers which can skew results if not addressed properly.
- Software Constraints: Not all statistical software packages are equipped to handle large datasets efficiently.
Steps to Perform Bayesian Inference on Big Data
1. Data Collection and Preparation
The first step in performing Bayesian inference is collecting and preparing your large dataset. This process involves:
- Identifying Sources: Determine the sources of your data, which may include databases, APIs, or streaming data.
- Data Cleaning: Clean your data to remove inconsistencies, duplicates, and outliers that may affect the analysis.
- Data Transformation: Transform your data into a suitable format for analysis, which may include normalization or encoding categorical variables.
2. Choosing the Right Model
Once your data is prepared, selecting an appropriate model is crucial. Bayesian models can vary widely, from simple linear regressions to complex hierarchical models. Factors to consider include:
- Data Type: The type of data (continuous, discrete, categorical) will guide your model choice.
- Prior Beliefs: Consider what prior knowledge exists and how it can inform your model.
- Complexity vs. Interpretability: Balancing a model’s complexity with interpretability is vital, especially in big data contexts.
3. Selecting Priors
One of the biggest advantages of Bayesian inference is the ability to incorporate prior distributions. Prior distributions represent your beliefs before observing the data. The choice of prior can greatly influence the posterior results:
- Non-informative Priors: Useful when no prior opinion exists about the parameters being estimated.
- Informative Priors: When there is existing knowledge or historical data, these priors can lead to better estimates.
4. Computation Techniques
Given the challenges of scaling Bayesian inference to big data, advanced computational techniques are often necessary:
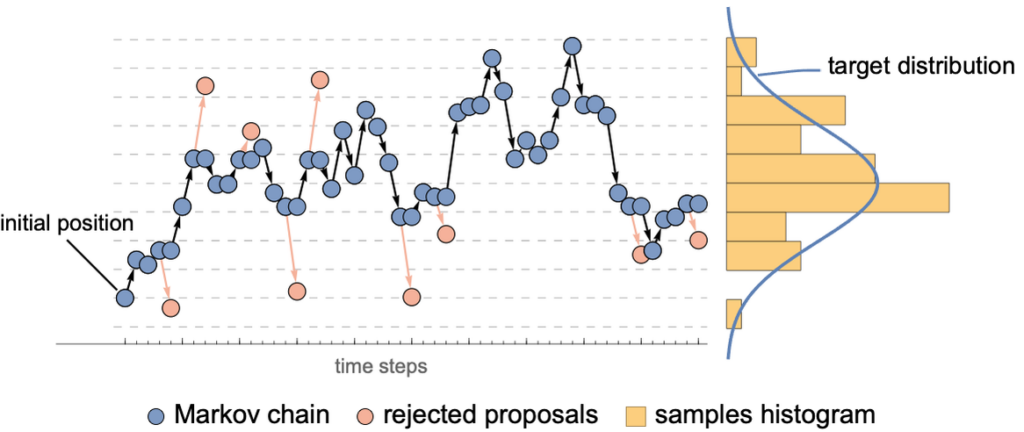
- Markov Chain Monte Carlo (MCMC): This method allows for the approximation of posterior distributions, even in multi-dimensional spaces.
- Variational Inference: A faster alternative to MCMC that aims to approximate the posterior distribution by transforming it into an optimization problem.
- Approximate Bayesian Computation (ABC): A family of algorithms that focuses on simulations of the data generating process to estimate the posterior.
5. Model Evaluation
After fitting the model, evaluating its performance and the quality of the inferences is essential. Methods for model evaluation include:
- Posterior Predictive Checks: Compare observed data with replicated data from the posterior predictive distribution to assess how well the model captures the observed data structure.
- Bayes Factors: Use Bayes factors to compare models. A Bayes factor greater than 1 supports one model over another.
- Cross-Validation: Split your dataset into training and testing subsets to validate the model’s predictive power.
6. Interpretation of Results
The final step is interpreting the results from your posterior distributions. Effective communication of these results is crucial for stakeholders. Points to keep in mind include:
- Credible Intervals: Use credible intervals to convey the uncertainty in your estimates, akin to confidence intervals in frequentist statistics.
- Decision Making: Integrate Bayesian results into decision-making frameworks or business processes.
- Visualization: Visualize your parameters and distributions using plots to make complex data more understandable.
Tools and Software for Bayesian Inference on Big Data
Several tools and software packages can facilitate Bayesian inference on massive datasets:
- Stan: A state-of-the-art platform for statistical modeling and high-performance statistical computation.
- PyMC3: An open-source probabilistic programming framework in Python that utilizes MCMC algorithms.
- Tidybayes: A package that allows the use of tidy principles in Bayesian analysis.
- H2O.ai: Provides scalable machine learning and statistical modeling tools tailored for big data.
Case Studies and Applications
Implementing Bayesian inference in the realm of big data analytics has numerous practical applications:
- Healthcare: Bayesian methods can improve diagnostic tools by integrating data from diverse sources, including medical imaging and patient history.
- Finance: Analysts use Bayesian inference to forecast stock prices and market trends by updating beliefs with real-time data.
- Marketing: Companies leverage Bayesian networks to predict customer behavior and tailor marketing strategies accordingly.
Conclusion of Steps
By following the outlined steps and utilizing appropriate tools, researchers and analysts can successfully perform Bayesian inference on large big data datasets. The iterative nature of Bayesian inference allows for a robust framework for incorporating new information, making it a powerful tool in the era of big data.
Leveraging Bayesian inference techniques on large Big Data datasets requires careful consideration of computational efficiency, scalability, and model complexity. By implementing parallel processing, optimization algorithms, and distributed computing, organizations can extract valuable insights and make informed decisions from massive amounts of data with high accuracy and reliability. Prioritizing the balance between accuracy and efficiency is crucial to successfully applying Bayesian inference in the realm of Big Data analysis.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 The Role of Data Warehousing in Big Data
The Role of Data Warehousing in Big Data
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Big Data vs. Traditional Data: What’s the Difference?
Big Data vs. Traditional Data: What’s the Difference?
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 The Evolution of Big Data Technologies: Past, Present, and Future
The Evolution of Big Data Technologies: Past, Present, and Future
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?