Data drift monitoring is an essential aspect of managing and maintaining the performance of big data models. As big data continues to grow and evolve, it is crucial to ensure that the data being utilized remains relevant and accurate for making informed decisions. In this context, data drift refers to the gradual change in data distribution over time, which can impact the effectiveness of machine learning models. Monitoring data drift involves continuously assessing and comparing the incoming data with the original training data to identify any discrepancies. By implementing robust data drift monitoring techniques, organizations can proactively detect and address issues, ensuring the continued reliability and relevance of their big data models.
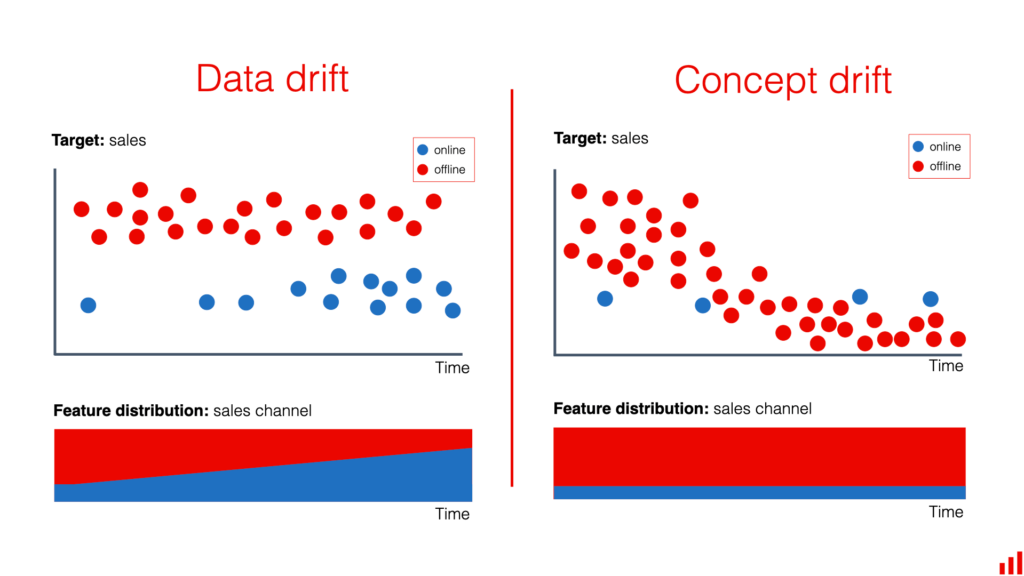
Data drift refers to the phenomenon where the statistical properties of the input data to a machine learning model change over time, potentially degrading its performance. In the realm of big data, where models are developed and deployed at scale, monitoring for data drift becomes crucial to maintain model accuracy and reliability. In this article, we will explore a comprehensive approach to data drift monitoring in big data settings, detailing methods, tools, and best practices.
Understanding Data Drift
Before diving into monitoring techniques, it’s important to understand what data drift entails. Data drift can be broadly categorized into two types:
- Covariate Drift: This occurs when the input data distribution changes, but the relationship between the input and output variables remains the same.
- Label Drift: This happens when the distribution of the target variable changes, indicating a shift in the underlying concept or behavior being modeled.
Recognizing these types of drift is essential for identifying appropriate monitoring strategies.
Why is Data Drift Monitoring Important?
Monitoring for data drift is critical for several reasons:
- Model Performance: A model trained on outdated data may provide inaccurate predictions, leading to poor decision-making.
- Stakeholder Trust: Continuous monitoring builds trust with stakeholders by ensuring model reliability.
- Risk Mitigation: Identifying data drift early can help mitigate potential risks related to faulty predictions.
Techniques for Monitoring Data Drift
There are various techniques used for data drift monitoring, each suited to different scenarios. Here are some effective methods:
1. Statistical Tests
One of the fundamental approaches to detecting data drift is using statistical tests. Here are a few commonly used tests:
- Kolmogorov-Smirnov Test: A non-parametric test that compares the cumulative distributions of two samples to assess whether they differ significantly.
- Chi-Squared Test: Useful for categorical features, it assesses whether the distribution of categorical variables has changed.
- Earth Mover’s Distance (EMD): Measures the minimum transportation cost required to transform one distribution into another, providing a quantitative measure of drift.
2. Visualization Techniques
Visualizing data is a powerful way to identify drift. Techniques include:
- Histograms: Compare the distributions of training and incoming data over time.
- Box Plots: Identify changes in median and variability of features.
- Density Plots: Visualize the probability density function of numeric features and highlight changes.
3. Machine Learning Models for Drift Detection
Advanced monitoring techniques involve deploying machine learning models explicitly trained to detect data drift. Some methods include:
- Concept Drift Detectors: Models that learn to anticipate and recognize changes in the data patterns.
- Autoencoders: A form of neural network that can reconstruct its input. A significant reconstruction error may indicate drift.
4. Monitoring Tools
There are several tools available that facilitate data drift monitoring:
- Alibi Detect: An open-source Python library for monitoring model performance and detecting drift.
- Microsoft’s DMT (Drift Monitoring Toolkit): A toolkit designed to monitor data drift in real-time for deployed models.
- Weights & Biases: Provides tools for visualizing and tracking experiment parameters, including drift.
Implementing a Data Drift Monitoring Strategy
To effectively monitor data drift in big data environments, consider the following steps:
Step 1: Baseline Establishment
Establish a baseline by analyzing the training dataset to capture its statistical properties. This includes mean, variance, distribution shape, and feature correlations.
Step 2: Continuous Data Collection
Set up a continuous data collection mechanism for incoming data once the model is deployed. This data will serve as the basis for ongoing drift analysis.
Step 3: Selection of Monitoring Techniques
Choose the appropriate monitoring techniques based on the characteristics of your data and the specific objectives of your model. A combination of statistical tests, visualization methods, and machine learning approaches can provide a robust monitoring infrastructure.
Step 4: Create Alerts and Thresholds
Develop a system for alerts when a certain threshold of drift is detected. This proactive approach enables quick responses to performance issues.
Step 5: Regular Review and Model Retraining
Regularly review drift monitoring results and schedule periodic model retraining sessions. Use new data to retrain models and update baselines as necessary.
Best Practices for Data Drift Monitoring
Implementing the right strategies is vital for effective data drift monitoring. Here are some best practices:
- Automate Monitoring: Use automated tools and frameworks for continuous monitoring instead of manual checks.
- Document Changes: Keep a comprehensive record of data characteristics over time. This can provide contextual information during drift incidents.
- Engage Stakeholders: Keep relevant stakeholders informed about drift incidents and their implications on model performance.
- Integrate Drift Monitoring in CI/CD Pipelines: Integrate your monitoring solutions into continuous integration and deployment pipelines for real-time insights.
Conclusion
Data drift is an inevitable occurrence in the world of big data and machine learning. Establishing a robust data drift monitoring framework is essential for ensuring sustained model performance. By understanding data drift, employing various monitoring techniques, and following best practices, organizations can proactively detect and mitigate drift, ultimately enhancing their decision-making processes based on machine learning insights.
Implementing robust data drift monitoring mechanisms in Big Data models is crucial for ensuring the accuracy and relevance of insights derived from constantly evolving datasets. By continuously evaluating and adapting models to changing data patterns, organizations can maintain the effectiveness and reliability of their Big Data analytics solutions, ultimately maximizing the value of their data-driven decision-making processes.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works