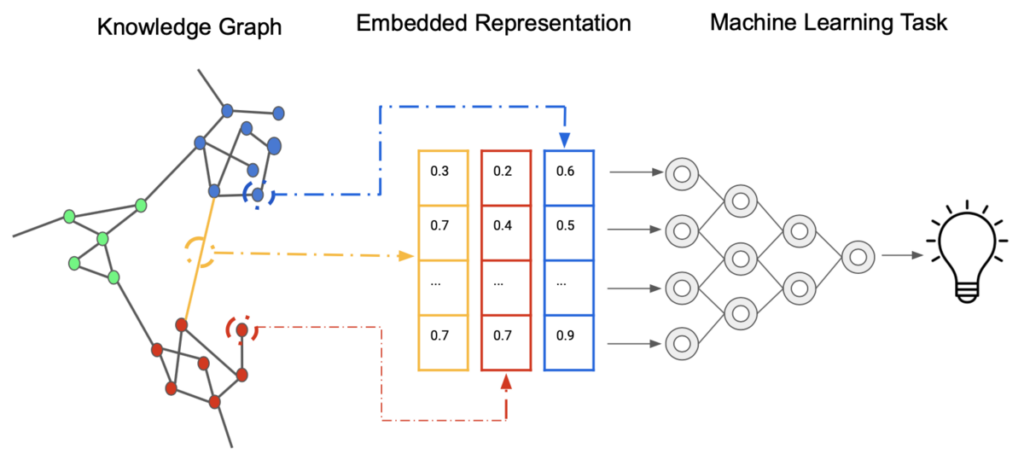
Knowledge graph embedding is a powerful technique used in Big Data reasoning to represent structured information in a more meaningful and efficient way. By encoding entities and relationships as continuous vectors in a lower-dimensional space, knowledge graph embedding enables machines to understand complex relationships, make accurate predictions, and perform advanced reasoning tasks. In this article, we will explore the importance of knowledge graph embedding in the context of Big Data, discussing its applications, challenges, and best practices for optimizing performance and extracting valuable insights from large-scale datasets.
Knowledge Graph Embedding (KGE) is a vital technique in the field of Big Data reasoning. It entails mapping knowledge graph entities and relationships into a continuous vector space to enable various machine learning applications. In this article, we will explore detailed steps to perform Knowledge Graph Embedding effectively, covering various methods and best practices tailored for processing large datasets.
Understanding Knowledge Graphs
A Knowledge Graph is a structured representation of knowledge consisting of entities (nodes) and their relationships (edges). Publicly available knowledge graphs, such as Wikidata or Freebase, serve as rich datasets, but for effective reasoning, we must convert them into a format suitable for machine learning. This poses significant challenges, particularly when working with Big Data due to its vastness and complexity.
Why Knowledge Graph Embedding Matters in Big Data
In traditional knowledge representation, reasoning and inference can become computationally expensive with the increase in data size. Knowledge Graph Embedding addresses these challenges by converting the graph structure into embedding vectors, making it easier for algorithms to process and reason over large amounts of data. By preserving semantic relationships, KGE helps in tasks such as recommendation systems, predictive analytics, and improved search functionalities.
Steps to Perform Knowledge Graph Embedding
1. Data Preparation
The first step in Knowledge Graph Embedding involves data preparation. This includes:
- Data Cleaning: Remove duplicates, incorrect entries, and irrelevant data.
- Data Transformation: Convert the data into a suitable format for processing, usually in triples (head, relation, tail).
- Data Splitting: Divide your dataset into training, validation, and test sets to evaluate the performance of your model.
2. Choosing the Right Knowledge Graph Embedding Technique
There are several methods for performing KGE. Choosing the right one depends on the nature of your dataset and the specific issues you want to solve. Common techniques include:
- Translational Models: Models like TransE, TransH, and TransR that represent relationships as translations in the embedding space.
- Tensor Factorization Models: Techniques like RESCAL and DistMult that utilize tensor decomposition to represent interactions in higher dimensions.
- Neural Network Models: More complex methods such as ConvE and ComplEx, which leverage neural networks for learning more expressive embeddings.
3. Implementing the KGE Model
Once you have selected a technique, the next step is to implement your KGE model. Here is a simple workflow to follow:
- Select a Framework: Use libraries such as OpenKE, DGL-KE, or PyTorch for implementing your KGE algorithms, especially for high-dimensional representation.
- Model Configuration: Set hyperparameters including learning rate, batch size, and the number of epochs for training. Fine-tuning these parameters can significantly affect the model performance.
- Training: Feed the training data into the model for feature extraction. Monitor performance metrics, such as Mean Rank and Hit Rate, to evaluate learning.
4. Evaluating the Knowledge Graph Embeddings
Once the KGE model is trained, it is essential to evaluate its effectiveness:
- Link Prediction: Test the model’s ability to predict missing links in the knowledge graph. This is done by querying the embedding space and analyzing the scores for potential relationships.
- Entity Classification: Check how well the model can classify entities based on their embeddings. This can be useful in predicting the category or traits of unknown entities.
You can utilize metrics such as Mean Average Precision (MAP), Area under ROC Curve (AUC), and F1 Score to gauge performance quantitatively.
5. Scaling for Big Data
With large datasets, efficiency becomes crucial. Here are methods to scale your KGE processes:
- Use of Distributed Computing: Leverage frameworks like Apache Spark for parallel processing. This can significantly speed up both training and inference phases.
- Batch Processing: If your dataset is voluminous, consider using batch processing or mini-batches to optimize memory usage and training time.
6. Post-Processing and Fine-Tuning
Once the initial training is complete, evaluative tactics need to be taken to enhance your KGE model:
- Fine-Tuning: Adjust hyperparameters and experiment with different architectures to achieve better results.
- Visualization: Use tools like t-SNE or UMAP to visualize the embeddings and assess how well the relationships are captured.
Addressing Challenges in Knowledge Graph Embedding
While performing KGE on big data, several challenges can arise:
1. Sparsity of Data
Datasets may be sparse, leading to performance issues. Entity Clustering and Link Prediction strategies can help enrich the graph with contextual relationships, thereby improving embeddings.
2. Scalability Issues
As the volume of data increases, computational efficiency becomes paramount. Using GPU acceleration, cloud computing, or optimized algorithms specifically designed for large-scale data can alleviate this challenge.
3. Overfitting
Overfitting is a common risk when using deep learning models. To mitigate this, consider using techniques such as dropout, L2 regularization, and cross-validation. Keeping some amount of your training set for validation can provide insight into model performance and guide adjustments.
Applications of Knowledge Graph Embedding in Big Data
Knowledge Graph Embedding has numerous applications in various sectors:
- Recommendation Systems: By understanding the relationships between different products and user preferences, KGE can enhance the accuracy of recommendations.
- Search Engines: Search result ranking based on graph embeddings can improve user experience by contextualizing results.
- Fraud Detection: Analyzing relationships and user behaviors can help identify anomalies and prevent fraudulent activities.
Conclusion
Exploring Knowledge Graph Embedding for Big Data reasoning is both a theoretical and practical endeavor. The methodologies outlined above provide a comprehensive approach to handling large-scale knowledge graphs. By leveraging efficient algorithms and strategies for embedding, organizations can extract valuable insights and facilitate informed decision-making based on their data.
Knowledge graph embedding offers a powerful approach for enhancing big data reasoning by capturing complex relationships and patterns within large datasets. By leveraging techniques such as node embedding and link prediction, organizations can derive valuable insights and make more informed decisions based on the interconnected nature of their data. As the volume and complexity of big data continue to grow, incorporating knowledge graph embedding into analytical workflows will be crucial for unlocking the full potential of data-driven decision-making.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI