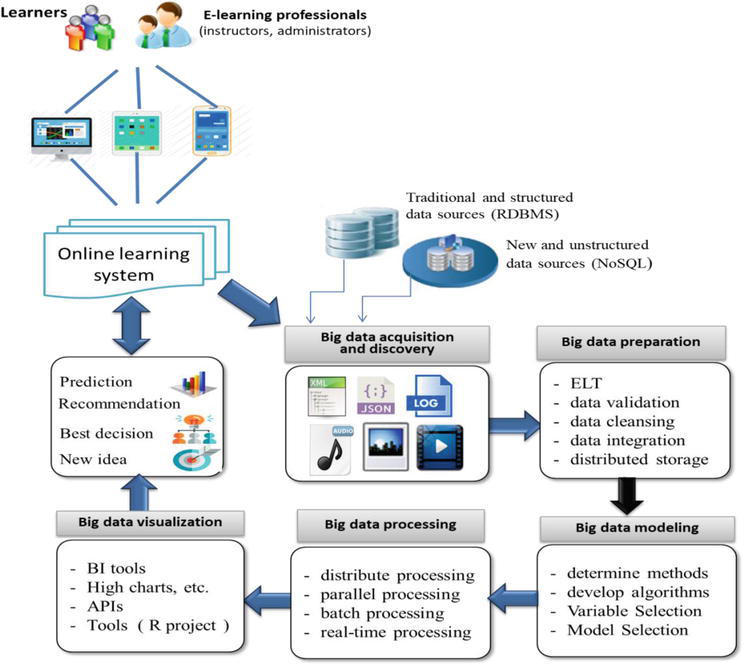
Performing online learning on large Big Data streams is a critical aspect of leveraging the full potential of Big Data analytics. With the exponential growth of data being generated in various industries, the ability to continuously update and optimize predictive models in real-time is essential for making timely and accurate decisions. In this process, data is constantly flowing in at high velocity and the models need to adjust and adapt automatically to capture the latest trends and patterns. This dynamic and scalable approach to learning allows organizations to extract valuable insights from massive streams of data and stay ahead of the competition. In this context, implementing online learning techniques on Big Data streams is crucial for achieving data-driven success in the fast-paced digital world.
In today’s data-driven world, the ability to perform online learning on large big data streams has become a critical capability for businesses and organizations striving to remain competitive. Online learning refers to the process where models are continuously updated as new data comes in, allowing organizations to adapt to changes quickly. In this article, we will explore the methodologies, frameworks, and tools required to effectively implement online learning for big data streams.
Understanding Online Learning in Big Data Context
Online learning is particularly relevant when dealing with big data streams because of the volume, velocity, and variability of data produced. Unlike traditional batch learning, where models are trained on a fixed dataset, online learning dynamically ingests data in real-time. This is essential in situations where data is continuously generated from multiple sources, such as social media, financial transactions, or IoT devices.
The core principle of online learning is to update the model incrementally as new data arrives. This process enables organizations to achieve better performance and maintain accuracy over time as the model evolves with the incoming data.
Key Algorithms for Online Learning
Several algorithms are well-suited for online learning, which can effectively handle the continuous influx of big data. Below are some prominent algorithms:
- Stochastic Gradient Descent (SGD): This algorithm updates model parameters incrementally for each data point, making it a popular choice for large datasets.
- Passive-Aggressive Algorithms: These are particularly effective for classification problems and incrementally update weights based on the errors made in predictions.
- Online Random Forest: This method builds a set of decision trees incrementally, allowing for robust classification and regression on streaming data.
- Adaptive Learning Rate Methods: Techniques like AdaGrad, RMSProp, and Adam can adjust learning rates during model updates to optimize learning performance.
Frameworks and Tools for Online Learning
To implement online learning on large big data streams, various frameworks and tools are at your disposal. Here are some of the leading options:
Apache Flink
Apache Flink is a powerful stream processing framework that allows for real-time data processing and online learning. It supports stateful computations, enabling the development of complex event-driven applications.
Flink’s machine learning library, FLINK-ML, provides algorithms that can be utilized for online learning tasks. Its ability to handle large-scale data while ensuring low-latency processing makes it an excellent choice.
Apache Spark Streaming
Apache Spark Streaming offers micro-batch processing of data streams, which can be advantageous for certain online learning applications. While it is not purely online (incremental) learning, it allows for continuous training of models using mini-batches of data.
Spark’s MLLib provides support for various machine learning algorithms, making it easy to implement online learning strategies with considerable scalability.
TensorFlow and Keras
TensorFlow along with Keras can also be used for online learning. TensorFlow supports the creation of custom data input pipelines that can operate in a streaming fashion. Leveraging these frameworks, you can build neural networks that learn incrementally from incoming data streams.
Scikit-learn and River
While Scikit-learn is more oriented towards batch learning, the River library is specifically designed for online learning. It provides a comprehensive set of algorithms for classification, regression, and time-series forecasting, making it ideal for handling streaming data in Python.
Strategies for Implementing Online Learning on Big Data Streams
To effectively perform online learning on large big data streams, the following strategies can be adopted:
1. Data Preprocessing
Data preprocessing is crucial for ensuring high-quality input for your learning models. Clean the data stream by removing noise, handling missing values, and normalizing features. This step can significantly enhance the performance of online learning algorithms.
2. Feature Selection and Engineering
Given the vast amount of data generated, feature selection becomes vital. Identify the most relevant features that influence the outcomes of your model. Additionally, consider feature engineering techniques to create new features that can improve model accuracy.
3. Model Design
Select the right model architecture tailored for online learning. Depending on your domain and data type, this might involve choosing simpler models that can quickly adapt to changes or leveraging complex models that require substantial resources.
4. Regularization Techniques
Implement regularization techniques to prevent overfitting as the model learns from new data. Methods like L1 and L2 regularization help maintain generalization while adapting to the nuances of data streams.
5. Continuous Evaluation
Establish metrics for continuous evaluation of model performance. Metrics such as precision, recall, and F1-score should be regularly updated as new batches of data are processed. This practice will help you make informed decisions about retraining or tuning your models.
Challenges in Online Learning with Big Data Streams
While online learning presents unique advantages, it also comes with its share of challenges:
1. Concept Drift
Concept drift occurs when the statistical properties of the target variable change over time in unforeseen ways. Models that perform well initially may degrade in performance as data patterns evolve. Implementing mechanisms for detecting concept drift is essential for maintaining model reliability.
2. Scalability
Scaling models to handle growing data streams efficiently can be challenging. Effective resource management and implementation of distributed algorithms become crucial to optimize computation without compromising performance.
3. Latency Requirements
For many applications, especially in industries like finance and healthcare, real-time latency is crucial. Balancing the trade-off between model complexity and responsiveness is a fundamental challenge when implementing online learning.
Best Practices for Online Learning on Big Data Streams
To maximize the effectiveness of online learning systems on big data streams, consider the following best practices:
1. Incremental Model Updates
Regularly update models incrementally rather than retraining from scratch. This approach conserves computational resources and enables the model to adapt to new data trends more seamlessly.
2. Use Ensemble Methods
Ensemble methods like boosting and bagging can be employed to enhance the robustness and accuracy of predictions on streaming data. These methods combine the predictions of multiple weak learners to produce a stronger model.
3. Implement Regular Feedback Loops
Incorporate mechanisms for real-time feedback from users or systems to refine models continuously. Feedback allows for timely adjustments and highlights areas for improvement.
4. Monitoring and Alerting
Set up monitoring systems to track model performance against selected metrics actively. Incorporate alerting mechanisms to promptly notify data scientists or ML engineers when performance drops below acceptable thresholds.
Conclusion
In the ever-evolving landscape of big data, the ability to perform online learning on large data streams stands as a significant competitive advantage. By understanding the methodologies, tools, and best practices outlined above, organizations can harness the power of real-time data learning to drive innovation and efficiency.
Performing online learning on large big data streams is crucial in the context of Big Data to enable real-time insights and decision-making. By utilizing advanced algorithms and optimization techniques, organizations can efficiently process and analyze massive amounts of data to extract valuable knowledge and enhance business operations. Embracing online learning on big data streams empowers businesses to stay agile, responsive, and competitive in today’s rapidly evolving digital landscape.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works
 The Impact of Big Data on Financial Services and Banking
The Impact of Big Data on Financial Services and Banking
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges