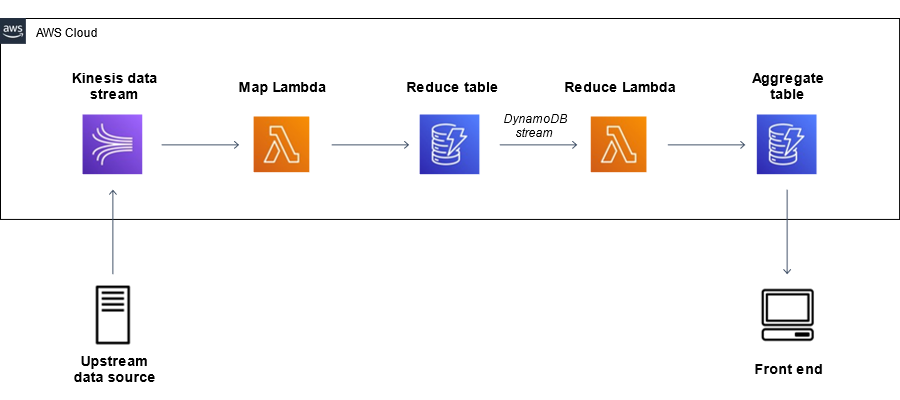
In the realm of Big Data, real-time data aggregation is a crucial process that enables organizations to effectively analyze and derive insights from massive volumes of data in motion. By continuously processing, collecting, and summarizing incoming data streams in real-time, businesses can gain instant visibility into trends, patterns, and anomalies. This enables timely decision-making, proactive problem-solving, and the ability to respond swiftly to changing circumstances. In this article, we will explore the key components and best practices for performing real-time data aggregation in Big Data systems, highlighting its significance in driving data-driven strategies and enhancing operational efficiency.
Understanding Real-Time Data Aggregation
Real-time data aggregation involves the process of collecting and summarizing data from various sources within Big Data systems as it is generated. This enables businesses to gain immediate insights and make informed decisions quickly. The primary goal of real-time data aggregation is to provide analytics and insights without significant delays.
The Importance of Real-Time Data Aggregation
In today’s data-driven world, the ability to synthesize data in real-time is crucial for organizations looking to enhance their operational efficiency. Real-time data aggregation allows businesses to:
- Identify trends and anomalies as they occur.
- Improve customer experience by providing instant feedback.
- Enhance decision-making capabilities with timely information.
- Optimize resource allocation and operational processes.
Key Techniques for Real-Time Data Aggregation
Several techniques can be employed to perform real-time data aggregation effectively:
1. Stream Processing
Stream processing is a method that processes data in real-time by continuously inputting, analyzing, and aggregating data streams. Popular platforms for stream processing include:
- Apache Kafka: A distributed streaming platform that allows you to publish and subscribe to streams of records.
- Apache Flink: A framework and distributed processing engine for stateful computations over data streams.
- Apache Spark Streaming: An extension of Apache Spark that enables scalable and fault-tolerant stream processing.
2. Batch Layer Approach
The Lambda architecture utilizes a Batch Layer to provide historical data analysis, allowing for real-time views on top of massive data sets. It combines batch processing with real-time processing for comprehensive insights. This method helps in aggregating data over time while providing real-time capabilities simultaneously.
3. Complex Event Processing (CEP)
Complex Event Processing allows for the real-time detection of patterns and correlations among streams of events. Time-sensitive events can be analyzed with a focus on immediate results, and tools like Esper and Apache Storm are often utilized for this technique.
Choosing the Right Tools for Data Aggregation
To effectively perform real-time data aggregation, you must choose the right tools that align with your business needs and data architecture. Here are some essential tools:
1. Apache NiFi
Apache NiFi is a powerful data integration tool designed for the automation of data flow between systems. It supports data routing, transformation, and system mediation logic, making it suitable for real-time data tasks.
2. Apache Kinesis
A managed service by Amazon, Amazon Kinesis allows for the real-time processing of streaming data at scale. It enables real-time analytics and can easily integrate with other AWS services for enhanced functionalities.
3. Google Cloud Dataflow
Google Cloud Dataflow is a fully managed service designed for stream and batch processing. It provides a serverless programming model that allows developers to build data pipelines for both real-time and batch data processing.
Implementing Real-Time Data Aggregation
Now that you understand the techniques and tools, let’s dig into the implementation process for performing real-time data aggregation in your Big Data systems.
Step 1: Define Use Cases
Before diving into implementation, identify and define the use cases for real-time data aggregation in your organization. Common use cases include fraud detection, customer sentiment analysis, live operational dashboards, and more.
Step 2: Collect Data from Various Sources
Aggregate data from diverse sources, such as transactional databases, IoT devices, applications, and social media. Use message brokers like Apache Kafka to handle the ingestion of data from these sources seamlessly.
Step 3: Process and Transform Data
Utilize stream processing frameworks (like Apache Flink or Spark Streaming) to process the incoming data streams. Transform and cleanse data to ensure that it meets the specifications required for aggregation.
Step 4: Aggregate Data in Real-Time
Employ aggregation techniques such as averaging, summing, or counting records to summarize the data. Store the results in a suitable database or data warehouse that supports quick querying (e.g., Amazon Redshift, Google BigQuery).
Step 5: Visualize Results for Insights
After aggregating data, visualize it using analytics tools like Tableau, Power BI, or built-in dashboard capabilities of platforms like Google Data Studio or Kibana. This step converts raw aggregated data into usable insights for your team.
Step 6: Monitor and Optimize
Continuous monitoring is critical to ensure that the aggregation process is functioning optimally. Implement logging and alerting mechanisms to identify errors or performance bottlenecks. Regularly adjust and optimize your data aggregation processes based on performance metrics and system feedback.
Best Practices for Real-Time Data Aggregation
When working with real-time data aggregation, following best practices can significantly improve efficiency and effectiveness. Here are some key practices:
- Keep Data Fresh: Ensure that your aggregation processes are configured for minimal lag so that data remains relevant and actionable.
- Use Scalable Architecture: Deploy a scalable architecture that supports varying data loads and can scale based on traffic demands.
- Prioritize Data Security: Implement robust security measures, including encryption and access controls, to protect sensitive data during aggregation.
- Perform Regular Audits: Conduct periodic audits of your data aggregation processes to identify inefficiencies and areas for improvement.
- Train Your Team: Provide training for your staff on the tools and technologies involved in real-time data aggregation, emphasizing best practices.
Conclusion
By understanding the aspects discussed in this article, organizations can effectively implement real-time data aggregation within their Big Data systems to enhance decision-making, operational efficiency, and customer satisfaction. Adopting suitable methodologies, employing the right tools, and following best practices will ensure that organizations remain competitive in this data-driven landscape.
Real-time data aggregation in Big Data systems is a critical capability that enables organizations to process and analyze vast amounts of data rapidly and efficiently. By leveraging technologies such as stream processing and in-memory computing, businesses can derive valuable insights in real-time, enhancing decision-making and driving competitive advantages. Prioritizing performance, scalability, and data quality are key considerations for successful real-time data aggregation in the realm of Big Data.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 The Evolution of Big Data Technologies: Past, Present, and Future
The Evolution of Big Data Technologies: Past, Present, and Future
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics