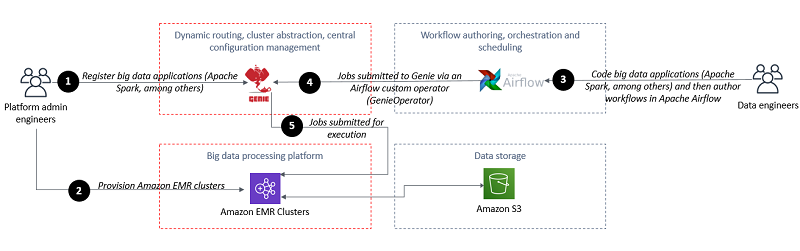
Apache Airflow is a powerful open-source platform that provides a versatile framework for orchestrating complex big data workflows. With its user-friendly interface and robust scheduling capabilities, Airflow allows data engineers to design, manage, and monitor data pipelines with ease. In this article, we will explore how to utilize Apache Airflow for big data workflows, enabling organizations to streamline their data processing tasks, optimize resource utilization, and achieve greater efficiency and scalability in handling large volumes of data.
What is Apache Airflow?
Apache Airflow is an open-source platform designed to programmatically author, schedule, and monitor workflows. It is particularly powerful for managing complex data pipelines in the realm of big data. With its ability to organize tasks into directed acyclic graphs (DAGs), Airflow allows users to efficiently structure and orchestrate workflows. Its modular architecture provides great flexibility and enables the integration of various tools and technologies in the big data ecosystem.
Key Features of Apache Airflow
Some of the key features that make Apache Airflow an excellent choice for managing big data workflows include:
- Dynamic Pipeline Generation: Airflow allows workflows to be defined as code, enabling users to create dynamic workflows that can be easily updated and customized.
- Built-in Scheduler: The scheduler executes tasks on a sequence and can handle dependencies between tasks, making it highly effective for managing intricate workflows.
- Monitoring and Logging: Users can monitor the status of workflows through a rich user interface, view logs, and troubleshoot issues more effectively.
- Extensible: Airflow is highly extensible; users can create custom operators and sensors to integrate with various big data tools such as Apache Spark, Hive, or Presto.
- Task Dependencies: You can set dependencies among tasks, ensuring they execute in the correct order.
Setting Up Apache Airflow
To start using Apache Airflow, you need to set it up on your environment. Here’s how:
Installation
Apache Airflow can be installed using pip, Docker, or by building it from source. The most common method is via pip:
pip install apache-airflowTo install specific providers for integrating with various big data tools, you can use:
pip install apache-airflow[mysql,postgres,google] # Example for MySQL, PostgreSQL, and Google integrationsConfiguration
After installation, you need to configure Airflow. This involves setting environment variables and configuring the airflow.cfg file, which contains various settings:
- Executor: The executor defines how tasks are executed. The default is the SequentialExecutor, which is suitable for testing, but for big data workloads, the LocalExecutor or CeleryExecutor is recommended.
- Database Connection: Configure the connection details for the backend database to store metadata.
- Web Server Configuration: Adjust settings for the web server to customize the UI experience.
Creating Your First DAG
A DAG (Directed Acyclic Graph) is a representation of your workflow in Airflow. Let’s create a simple DAG:
Define the DAG
Create a new Python file in the dags folder, e.g., my_first_dag.py. Here’s a basic example:
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from datetime import datetime
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1),
}
dag = DAG('my_first_dag', default_args=default_args, schedule_interval='@daily')
start = DummyOperator(task_id='start', dag=dag)
end = DummyOperator(task_id='end', dag=dag)
start >> end # Define task dependenciesThis example uses the DummyOperator to create a simple workflow where one task starts and another task ends.
Testing Your DAG
To test if your DAG is working correctly, use the command line interface:
airflow dags listThis command will show you a list of available DAGs. You can then trigger your DAG to see if it executes as expected:
airflow dags trigger my_first_dagIntegrating Apache Airflow with Big Data Tools
Apache Airflow can be easily integrated with various big data technologies. Here are a few common integrations:
Apache Spark
To streamline Spark jobs within your Airflow workflows, use the SparkSubmitOperator. Here’s a sample implementation:
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
spark_task = SparkSubmitOperator(
task_id='spark_job',
application='path/to/spark_application.py',
name='spark_job',
dag=dag
)
start >> spark_task >> endApache Hive
To execute Hive queries, use the HiveOperator. Here’s an example:
from airflow.providers.apache.hive.operators.hive import HiveOperator
hive_task = HiveOperator(
task_id='hive_query',
hql='SELECT * FROM my_table;',
hive_conn_id='my_hive_connection',
dag=dag
)
start >> hive_task >> endMonitoring Your Workflows
One of Airflow’s significant advantages is its web-based UI that provides comprehensive monitoring functionality:
- Logging: Each task has access to logs, which can be reviewed directly from the UI, assisting in troubleshooting.
- Task States: You can easily monitor the status of each task—whether it’s running, success, or failed.
- Graph View: Airflow’s graph view visualizes task dependencies, providing a clear representation of your workflows.
Best Practices for Using Apache Airflow in Big Data Workflows
Implementing best practices will help maximize the effectiveness of Apache Airflow in managing big data workflows:
- Keep DAGs Simple: Aim for readability by avoiding overly complex DAGs, which can lead to maintenance difficulties.
- Use Version Control: Store your DAG files in a version control system like Git to track changes and collaborate with team members.
- Handle Failures Gracefully: Implement retries and error handling strategies in your tasks to ensure resilience in case of failures.
- Optimize Task Execution: Ensure that tasks are lightweight and that resource allocation is managed effectively to optimize performance.
- Leverage Airflow’s Extensibility: Use custom operators and hooks to extend Airflow’s functionality based on your specific needs.
Common Issues and Troubleshooting
While using Apache Airflow, users may encounter certain common issues. Here are troubleshooting tips for those challenges:
DAG Not Appearing
Ensure your DAG file is located in the correct dags directory and check the logs for errors during parsing.
Task Failures
Examine the logs of the failed task to identify the root cause. Common reasons include incorrect parameters, resource constraints, or dependencies not being met.
Web Server Issues
If the web server is not responsive, check the Airflow configuration files, and verify that it is running under the correct port.
Conclusion
With a solid understanding of how to use Apache Airflow for managing big data workflows, you can leverage its capabilities to streamline your data processing tasks effectively. From setting up your first DAG to integrating with other big data tools, Airflow provides a comprehensive solution to orchestrate complex workflows, enhancing the efficiency of your big data projects.
Apache Airflow offers a robust solution for managing and orchestrating Big Data workflows efficiently. By utilizing its powerful features such as task scheduling, monitoring, and dependency management, organizations can streamline their data processing operations, improve productivity, and ensure the reliability of complex data pipelines. With its flexibility and scalability, Apache Airflow is a valuable tool for maximizing the performance and effectiveness of Big Data workflows in the ever-evolving landscape of data management.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI