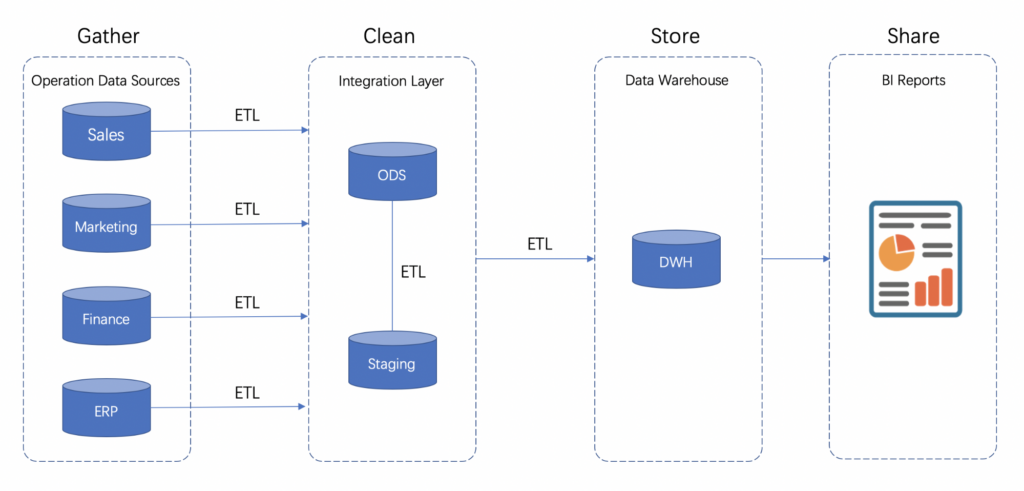
Apache Hudi is a powerful open-source data management framework designed for incremental data processing in the realm of Big Data. Leveraging the capabilities of Apache Hudi enables organizations to efficiently process and manage large volumes of data while ensuring data integrity and reliability. By providing features such as upserts, deletes, and schema evolution, Apache Hudi simplifies the process of handling constantly changing data sets and facilitates seamless incremental data processing. In this article, we will explore how to effectively utilize Apache Hudi to carry out incremental data processing tasks, highlighting its significance in the realm of Big Data analytics and data management.
In the realm of big data, managing data lakes and enabling real-time processing of massive datasets is a significant challenge. Fortunately, Apache Hudi (Hadoop Upserts Deletes and Incremental processing) provides an effective solution. It is tailored for transactional data processing on large datasets. This article delves deep into how to leverage Apache Hudi for incremental data processing, and why it stands out as an ideal choice for handling your big data use cases.
Understanding Apache Hudi
Apache Hudi is an open-source data management framework that simplifies storage and processing in big data environments. It supports several critical features:
- Upserts: Update existing records or insert new ones efficiently.
- Incremental Processing: Handle only new or changed data since the last update.
- Schema evolution: Adapt to changing data schemas without hassle.
- Time travel: Query historical versions of your data.
Setting Up Apache Hudi
Before diving into incremental data processing, you need to set up Apache Hudi. Here’s how you can do that:
Environment Requirements
Ensure you have the following components installed:
- Java 8 or higher
- Apache Spark 2.4 or higher
- Apache Hadoop
- Maven (for building Hudi, if required)
Installation Steps
- Download the latest Apache Hudi release from the official website.
- Extract the downloaded file to a specified directory.
- Set environment variables:
export HUDI_HOME=/path/to/hudi export PATH=$HUDI_HOME/bin:$PATH - Ensure that Hadoop and Spark are running properly.
Using Apache Hudi for Incremental Data Processing
Apache Hudi shines in incremental data processing, especially when working with large datasets. This functionality allows you to easily track changes and only process new records, thus saving time and resources.
Creating a Hudi Table
The first step towards managing incremental data is creating a Hudi table. Choose either the Copy on Write (COW) or Merge on Read (MOR) storage type based on your specific requirements.
spark.sql("CREATE TABLE hudi_table (
name STRING,
age INT,
ts TIMESTAMP,
PRIMARY KEY (name)
) USING Hudi
OPTIONS (
TYPE = 'MERGE_ON_READ',
HIVE_SYNC_ENABLED = 'true',
HIVE_TABLE = 'hudi_table'
)");
Ingesting Data
Data ingestion can be performed in two ways: bulk insert and incremental insert. Both methods allow you to manage and stream data efficiently.
Bulk Insert
spark.write.format("hudi")
.option("hoodie.table.name", "hudi_table")
.option("hoodie.operation", "bulk_insert")
.mode(SaveMode.Overwrite)
.save("/path/to/hudi_table");
Incremental Data Ingestion
For incremental ingestion, use the following method to add new records:
spark.write.format("hudi")
.option("hoodie.table.name", "hudi_table")
.option("hoodie.operation", "upsert")
.mode(SaveMode.Append)
.save("/path/to/hudi_table");
Querying Incremental Data
After ingesting data, you need to query the updated records. The Hudi incremental read operation allows analysts and data engineers to extract only the changed portions of the data:
val incrementalData = spark.read.format("hudi")
.option("hoodie.table.name", "hudi_table")
.option("hoodie.begin.instanttime", "20230201000000")
.option("hoodie.end.instanttime", "20230202000000")
.load("/path/to/hudi_table");
Here, `hoodie.begin.instanttime` and `hoodie.end.instanttime` parameters correspond to the timestamps of the changes you’re interested in.
Handling Schema Evolution
An essential feature of Apache Hudi is its capability for schema evolution. When your data structure changes, Hudi seamlessly manages these modifications. Here’s how to proceed:
- Modify your data schema, for instance, introducing a new field.
- Update your records accordingly:
spark.write.format("hudi") .option("hoodie.table.name", "hudi_table") .option("hoodie.operation", "upsert") .mode(SaveMode.Append) .save("/path/to/hudi_table"); - Hudi updates the schema automatically, preserving existing data.
Optimizing Hudi Incremental Queries
To ensure efficient performance while querying incremental data, consider the following optimization strategies:
- Partitioning: Partition your data based on temporal or logical attributes to speed up queries.
- Indexing: Leverage Hudi’s built-in indexing capabilities to enhance lookup speed for large datasets.
- File Sizing: Fine-tune your file sizing strategies to balance read and write performance.
Monitoring and Managing Your Hudi Tables
Proper monitoring of Apache Hudi tables is crucial for maintaining their performance and integrity. Tools like Apache Superset or DIP can visualize your data dynamics effectively. Keep track of the following:
- Table size: Monitor the size of your Hudi tables to prevent unnecessary overheads.
- Read/Write performance: Analyze the performance metrics of your queries and ingestion rates.
- Audit logs: Inspect audit logs for any failures or inconsistencies in data processing.
Conclusion
Utilizing Apache Hudi effectively for incremental data processing can significantly enhance your big data analytics. From seamless data ingestion to efficient querying and schema evolution, Hudi provides the capabilities needed to tackle modern data challenges. Adopting Hudi in your big data architecture will not only streamline your data operations but also empower your teams to make data-driven decisions faster and more efficiently.
Apache Hudi provides a powerful solution for incremental data processing in Big Data environments, offering efficient ingestion, updates, and incremental queries while maintaining data integrity and consistency. By leveraging Hudi’s capabilities, organizations can effectively manage changing data streams and derive valuable insights in real-time, making it an invaluable tool for scalable and efficient data processing workflows.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works
 The Impact of Big Data on Financial Services and Banking
The Impact of Big Data on Financial Services and Banking