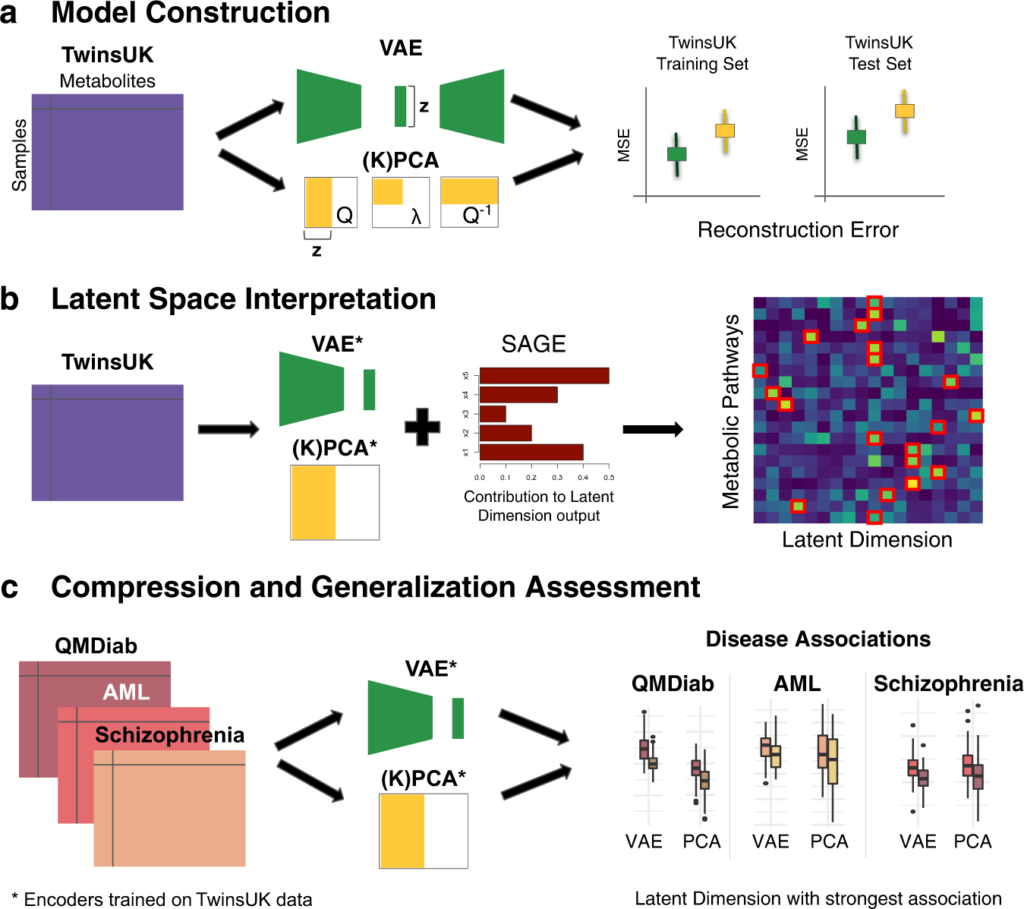
Variational Autoencoders (VAEs) have emerged as a powerful tool in the field of deep learning for large-scale data compression. In the realm of Big Data, where massive amounts of information need to be processed and stored efficiently, VAEs offer a promising solution for reducing the dimensionality of complex datasets while retaining important features. This introduction will explore how VAEs can be harnessed to compress large-scale data effectively, making it easier to store, analyze, and manipulate vast amounts of information.
Understanding Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are a class of deep learning models designed for generating new data instances that resemble your training data. They are particularly powerful for unsupervised learning tasks and are widely used for generating images, audio, and other types of complex data. VAEs consist of two main components: the encoder and the decoder.
The encoder compresses input data into a lower-dimensional latent space, while the decoder reconstructs the data from this compressed representation. This process not only allows the VAE to learn the underlying distribution of the data but also facilitates data compression—making it an ideal choice for handling large-scale datasets that are often encountered in the realm of big data.
Why Use VAEs for Data Compression?
Implementing VAEs for data compression offers several advantages:
- Efficiency: VAEs can significantly reduce the dimensionality of data while preserving essential features, making them more manageable for storage and processing.
- Generative Capabilities: Unlike traditional compression methods, VAEs can generate new samples similar to training data, thus providing an extra layer of utility.
- Scalability: They can handle large datasets effectively, making them suitable for applications in fields like healthcare, finance, and social media.
Implementing Variational Autoencoders for Compression
To effectively implement VAEs for large-scale data compression, follow these steps:
1. Data Preparation
Begin with data collection, cleaning, and preprocessing. Large datasets often require significant effort to ensure quality and consistency. Consider the following steps:
- Normalize: Scale your data to improve the performance of the VAE.
- Feature Engineering: Extract relevant features that might improve the VAE’s ability to learn the data distribution.
2. Setting Up Your VAE Model
A typical VAE architecture includes:
- Encoder Network: This network takes the input data and transforms it into a latent distribution. It usually consists of several convolutional or fully connected layers.
- Latent Space: Represented as a Gaussian distribution defined by mean and variance parameters.
- Decoder Network: This reconstructs data from the latent space back into the original space.
3. Loss Function
The loss function in VAEs is crucial for effective training. It typically consists of two parts: the reconstruction loss and the Kullback-Leibler (KL) divergence.
The reconstruction loss measures how well the decoder can reconstruct the input data, while the KL divergence quantifies how closely the learned latent space distribution matches the prior distribution. The goal is to minimize the overall loss:
Loss = Reconstruction Loss + KL Divergence
4. Training the VAE
Train your VAE using an optimized algorithm like Adam or RMSprop. Ensure that you have substantial computational resources, especially when dealing with large-scale data, as training VAEs can be resource-intensive.
5. Data Compression and Reconstruction
After training, you can use the encoder to compress data into the latent space. The size of this latent representation is determined by the architecture you set up. Then, for decompression, the decoder reconstructs the original data from the latent representation.
6. Evaluating Compression Performance
Evaluate the performance of your VAE using metrics such as:
- Compression Ratio: The ratio of the original size to the compressed size.
- Reconstruction Error: Measuring how closely the reconstructed data matches the original data.
- Visual Quality: In case of images, visually inspect how well your VAE reconstructs the images.
Tuning Variational Autoencoders
The effectiveness of VAEs highly depends on tuning various hyperparameters such as:
- Latent Space Dimensionality: The size of the latent space determines how much information can be compressed. A smaller space leads to more lossy compression.
- Learning Rate: Employ a suitable learning rate to avoid overshooting during gradient descent.
- Batch Size: A larger batch size can speed up training but may require more memory.
Use Cases of VAEs in Large-Scale Data Compression
Variational Autoencoders have numerous applications in managing and compressing large-scale datasets:
1. Image Compression
VAEs can significantly compress image datasets by learning how to represent visual features efficiently. By training on large collections of images, VAEs can compress them while preserving essential details.
2. Natural Language Processing
In NLP, VAEs can be employed to generate word embeddings or summarize large texts efficiently. This aids in compressing the representation of textual data while maintaining its semantic meaning.
3. Anomaly Detection
In big data analytics, VAEs can be useful for detecting anomalies in large datasets. By learning the typical distribution of data, VAEs can identify data points that deviate significantly, indicating potential fraud or errors.
4. Healthcare Data Management
Healthcare generates vast amounts of data daily. Using VAEs, healthcare organizations can compress patient records efficiently while still having access to crucial information for analyses and predictions.
Conclusion
In summary, Variational Autoencoders represent a powerful method for large-scale data compression. Their ability to learn complex data distributions, coupled with generative capabilities, makes them highly suitable for many big data applications.
By understanding the principles behind VAEs and implementing them carefully, you can leverage their potential for efficient and effective data management strategies.
Variational Autoencoders offer a powerful solution for large-scale data compression in the realm of Big Data. By efficiently encoding and decoding complex data while capturing important features, VAEs enable significant reductions in storage requirements without significant loss of information. Their ability to handle high-dimensional data and adapt to different types of data make them valuable tools for optimizing storage and processing in Big Data applications. As the volume of data continues to grow, leveraging VAEs for data compression can lead to more scalable and efficient data management practices in the era of Big Data.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data