DataOps is a methodology that emphasizes the collaboration, communication, and integration of data operations within an organization. For Big Data Engineers working in the realm of Big Data, understanding and implementing DataOps practices is crucial to ensure the efficiency, scalability, and reliability of data processes. This approach involves streamlining workflows, automating tasks, and using agile principles to optimize the end-to-end data pipeline. In this guide, we will explore the key principles of DataOps specific to Big Data, along with best practices and tools that Big Data Engineers can leverage to successfully manage and maintain large data sets in today’s data-driven environment.
What is DataOps?
DataOps is a set of practices and tools designed to improve the speed, quality, and value of data analytics through an agile and collaborative approach. The methodology is inspired by DevOps, which aims to shorten the software development lifecycle. In the domain of Big Data, DataOps integrates processes involved in collecting, processing, and analyzing vast amounts of data to foster a more efficient data pipeline.
The Importance of DataOps in Big Data
As organizations increasingly rely on big data solutions to drive decision-making, the need for strong data management practices becomes crucial. DataOps helps tackle several challenges faced by big data engineers, such as:
- Data Silos: In many organizations, data is trapped in various systems. DataOps emphasizes collaboration and integration between teams, breaking down silos to deliver more cohesive data infrastructure.
- Data Quality: Ensuring the quality of data is paramount. DataOps incorporates continuous testing and validation of data, enabling engineers to identify and rectify issues swiftly.
- Speed to Insight: The agility of DataOps allows organizations to derive insights from data faster, significantly impacting decision-making processes.
Key Principles of DataOps
Understanding the foundational principles of DataOps is essential for big data engineers to successfully implement this approach. Here are the key principles highlighted in DataOps:
1. Automation
Automation is at the core of DataOps. By automating data processes such as ingestion, transformation, and analysis, teams can reduce manual errors and speed up the data pipeline. Tools that facilitate automation include:
- Data integration tools (e.g., Apache NiFi)
- Data testing frameworks (e.g., Great Expectations)
- CI/CD pipelines for data workflows (e.g., Jenkins)
2. Collaboration
DataOps fosters a collaborative culture between data engineers, analysts, and business stakeholders. This collaboration ensures that everyone’s requirements and insights are considered, leading to higher-quality data products. Techniques to encourage collaboration include:
- Regular cross-functional meetings
- Shared repositories for documentation and code
- Using collaboration tools such as Slack or Microsoft Teams
3. Continuous Improvement
In the world of DataOps, there’s always room for enhancement. Continuous feedback loops provide teams with insights into their workflows, allowing for iterative improvements. Practices that support this principle are:
- Regularly reviewing performance metrics
- Conducting retrospectives after project completion
- Establishing a culture that embraces experimentation
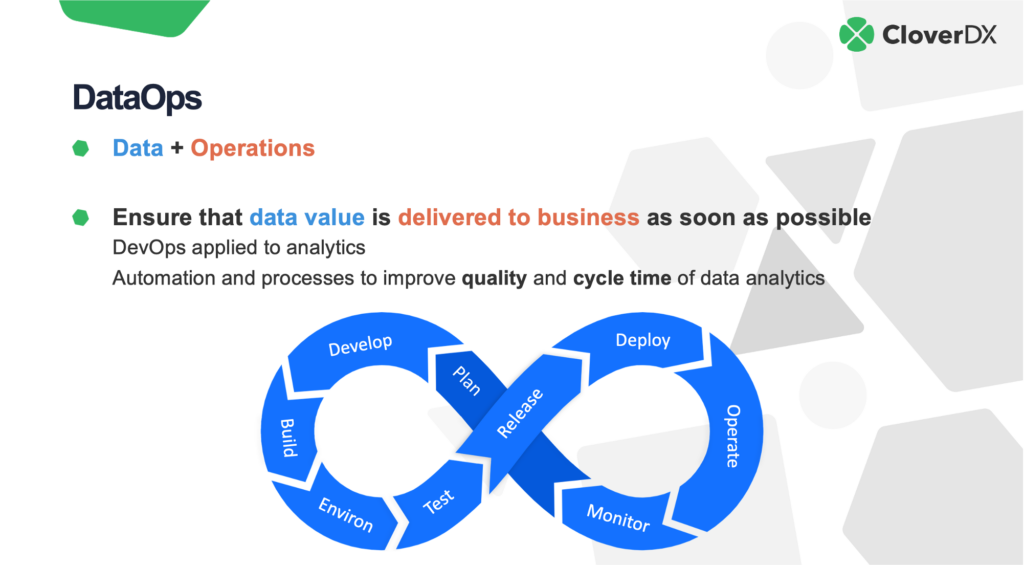
DataOps Lifecycle
The DataOps lifecycle encompasses several stages, each designed to optimize data workflows. Big data engineers should familiarize themselves with these stages:
1. Data Ingestion
The first step in the DataOps lifecycle is data ingestion. This involves collecting data from various sources, such as databases, APIs, and data lakes. Engineers employ data integration tools to extract, transform, and load (ETL) data efficiently.
2. Data Validation
Once data is ingested, it must be validated to ensure its quality. Automated testing frameworks can quantify data accuracy, consistency, and integrity, helping data engineers catch issues early in the data pipeline.
3. Data Transformation
After data validation, the next step is data transformation. This process involves modifying the data format to fit the analytics needs or business requirements. Techniques such as normalization, aggregation, and enrichment are utilized during this phase.
4. Data Analysis
Data analysis is where insights are derived from transformed data. By using data visualization tools and advanced analytics methodologies, big data engineers can present findings to stakeholders effectively.
5. Feedback and Iteration
Gathering feedback on data output is crucial for continuous improvement. This feedback loop involves collecting input from stakeholders, assessing the effectiveness of data products, and making necessary adjustments.
Tools and Technologies in DataOps
Big Data Engineers need to familiarize themselves with the different tools and technologies that facilitate DataOps. Here are some popular tools:
1. Data Integration Tools
These tools help automate the ingestion process. Examples include:
- Apache NiFi: Supports data flow automation.
- Talend: Offers a suite of data integration products.
- Informatica: Provides robust ETL capabilities.
2. Data Quality Tools
Ensuring data quality requires dedicated tools like:
- Great Expectations: A Python-based tool for validating data correctness.
- Apache Griffin: Helps monitor and profile data continuously.
- Talend Data Quality: Checks for data accuracy and consistency.
3. Data Visualization Tools
To communicate data insights effectively, engineers need visualization tools such as:
- Tableau: A popular data visualization software.
- Power BI: A business analytics tool by Microsoft.
- Looker: Provides data exploration capabilities.
Implementing DataOps in Big Data Engineering
Implementing DataOps is not without its challenges, but with the right strategy, big data engineers can overcome these hurdles. Here are some steps to facilitate a successful DataOps implementation:
1. Define Objectives
Start by defining clear objectives for your DataOps initiatives. This involves understanding the end goals, such as improving data quality, increasing speed to insight, or fostering better collaboration among teams.
2. Build a Cross-Functional Team
A successful DataOps program requires a diverse team comprising data engineers, analysts, data scientists, and business stakeholders. Each member should understand their role in the data pipeline and contribute to the program’s objectives.
3. Invest in Tools and Technology
Select and invest in the right tools to streamline data processes. The chosen tools should align with your objectives and facilitate automation, validation, and analysis.
4. Foster a Collaborative Culture
Encouraging a culture of collaboration among teams will yield vast improvements in productivity and innovation. Regular meetings and feedback sessions can enhance communication and alignment.
5. Measure and Monitor
Constantly measure the performance of your DataOps practices. Utilize Key Performance Indicators (KPIs) to assess progress and adjust strategies based on feedback.
The Future of DataOps in Big Data Engineering
As organizations continue to generate and harness vast amounts of data, the role of DataOps will become increasingly critical. Emerging trends in the field include:
- AI and Machine Learning Integration: Incorporating AI into DataOps processes can enhance efficiency in data analysis and predictive modeling.
- Real-Time Data Processing: The demand for instantaneous insights will drive the development of tools and strategies that cater to real-time data flows.
- Cloud-Native DataOps: With more organizations migrating to the cloud, DataOps will evolve to leverage cloud capabilities for scalability and flexibility.
Big Data Engineers embracing DataOps are well-positioned to drive their organizations toward superior data practices and competitive advantage. The confluence of data agility, quality, and collaboration will redefine how organizations utilize data analytics in the years to come.
Mastering DataOps principles is essential for Big Data engineers to effectively manage, orchestrate, and optimize data workflows in a dynamic and ever-evolving Big Data environment. By incorporating DataOps into their skill set, engineers can streamline processes, enhance collaboration, and ultimately drive greater insights and value from Big Data.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 The Evolution of Big Data Technologies: Past, Present, and Future
The Evolution of Big Data Technologies: Past, Present, and Future
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics