Processing high-dimensional data poses several challenges in the realm of Big Data analytics. As the volume of data continues to grow exponentially, it becomes increasingly complex to analyze and derive meaningful insights from datasets with a large number of dimensions. This presents obstacles such as increased computation time, high storage requirements, curse of dimensionality, and difficulty in visualizing or interpreting the data. Addressing these challenges is crucial for organizations looking to unlock the full potential of Big Data and harness its value for making informed decisions and driving innovation.
In the era of big data, organizations are inundated with vast amounts of information generated every second. Among the various challenges faced by data scientists, one of the most significant is efficiently processing high-dimensional data. High-dimensional datasets are those that contain a large number of variables (dimensions) relative to the number of observations. As dimensions increase, so do the complexities involved in analysis.
Understanding High-Dimensional Data
High-dimensional data often arises in various fields such as genomics, image processing, and natural language processing, where the number of features exceeds the number of samples available for analysis. This abundance of features can lead to several challenges, commonly referred to as the curse of dimensionality.
The Curse of Dimensionality
The curse of dimensionality refers to a phenomenon whereby the feature space becomes increasingly sparse as the number of dimensions grows. This sparsity complicates the analysis of data, making it harder to find meaningful patterns and relationships. Key issues arising from the curse of dimensionality include:
- Increased computational cost: The time and resources required to process high-dimensional data can become prohibitive, as traditional algorithms may not be efficient in such an expansive feature space.
- Overfitting: With a vast number of features, there is a heightened risk of creating models that capture noise rather than the underlying signal in the data.
- Model interpretability: As dimensions increase, understanding the relationships between variables becomes increasingly challenging, making it difficult to communicate findings effectively.
Data Sparsity and Inefficiency
High-dimensional datasets often result in data sparsity, where most of the feature space is unoccupied. This lack of dense data can lead to inefficiencies in data processing:
- Redundant features: High-dimensional datasets frequently encompass redundant and irrelevant features that do not contribute to the analysis, complicating the data processing pipeline.
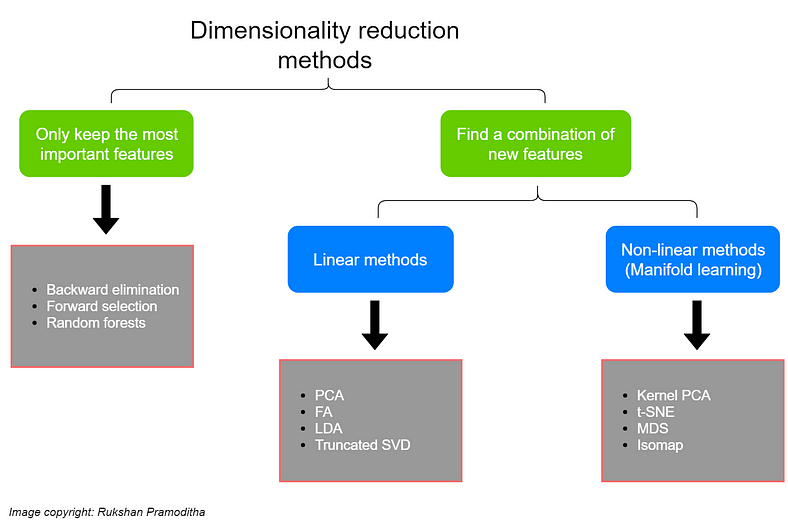
- Dimensionality reduction requirements: Before analyzing high-dimensional data, data scientists often need to perform dimensionality reduction using techniques like Principal Component Analysis (PCA) or t-SNE, which can introduce additional computational overhead.
Choosing the Right Algorithms
Not all machine learning algorithms perform equally well on high-dimensional data. Many algorithms struggle with high-dimensional feature spaces, leading to erroneous results or tasks that run considerably slower than expected:
- Linear algorithms: Linear models (like linear regression) may fall short when dealing with high-dimensional data as they rely heavily on the assumption of linearity. In contrast, algorithms like Random Forests or Support Vector Machines may yield better performance due to their capacity to capture complex relationships.
- Feature selection: Effective feature selection techniques must be employed to mitigate overfitting and the curse of dimensionality, which requires additional understanding and resources.
Scalability Issues
As data volumes increase in tandem with dimensionality, scalability becomes a critical obstacle. Traditional computation models may not adequately handle the exponentially growing datasets:
- Distributed computing challenges: While distributed computing frameworks (like Hadoop and Spark) can handle large datasets, ensuring they effectively manage high-dimensional data adds layers of complexity to the design and implementation.
- Memory constraints: High-dimensional datasets require significant memory for processing. Insufficient memory can lead to performance lags or even system crashes, hindering analysis.
Data Cleaning and Preprocessing Challenges
The necessity of data cleansing and preprocessing is magnified in high-dimensional datasets. This involves tasks such as handling missing values, filtering out noise, and normalizing data:
- Handling missing data: Missing features in high-dimensional data can greatly diminish model performance. The strategies employed for imputation need to be accurate and effective yet computationally feasible.
- Noise reduction: High-dimensional data is often plagued with noise which complicates analysis. Implementing noise filtering techniques in a high-dimensional context is a formidable task.
Visualization Challenges
Data visualization is a pivotal aspect of data analysis, yet visualizing high-dimensional data can be incredibly challenging:
- Loss of information: When attempting to visualize high-dimensional data (e.g., through 2D or 3D plots), there is an inherent risk of losing valuable information, which can lead to misinterpretation.
- Advanced visualization techniques: More advanced methods such as dimensionality reduction techniques (like t-SNE or UMAP) must be employed, but they may also yield different representations of data, which can be difficult to interpret.
Model Evaluation and Validation
Validating models built on high-dimensional data adds further complexity for data scientists:
- Cross-validation pitfalls: Standard cross-validation techniques might be inadequate because they can introduce additional variance when working with high-dimensional data.
- Evaluation metric selection: Choosing the right metrics to evaluate models can be challenging. Metrics that work effectively in lower dimensions may not provide meaningful insights in high-dimensional contexts.
The Importance of Domain Knowledge
To overcome many of the challenges associated with high-dimensional data, possessing a solid background in the relevant domain is crucial. Understanding the underlying biological, financial, or technical context can guide data scientists in making informed decisions about:
- Feature selection: Knowing which dimensions are more relevant can significantly enhance the model’s effectiveness and reduce computation times.
- Model appropriateness: Choosing the right algorithms that fit the specific characteristics of the data is easier with domain knowledge.
Using High-Dimensional Data Effectively
Despite the numerous challenges, organizations can employ several strategies to utilize high-dimensional data effectively:
- Feature engineering: Creating meaningful features based on domain knowledge can aid in reducing dimensionality while preserving essential information.
- Ensemble methods: Utilizing ensemble techniques can help in combining multiple models to improve predictions and robustness against overfitting.
Understanding these challenges is critical for organizations striving to extract meaningful insights from high-dimensional datasets. By leveraging proper techniques – such as effective preprocessing, feature selection, and advanced algorithms – businesses can uncover valuable patterns and drive data-driven decision-making.
In summary, processing high-dimensional data entails navigating a host of complex, inter-related challenges. As technology evolves and data continues to grow in dimensions and volume, organizations must be prepared to embrace these challenges head-on, optimizing their strategies for meaningful analysis of high-dimensional datasets.
The processing of high-dimensional data presents significant challenges in the realm of Big Data due to issues such as computational complexity, dimensionality curse, and interpretation limitations. Overcoming these challenges requires innovative approaches, advanced algorithms, and efficient data processing techniques to unlock the valuable insights hidden within high-dimensional datasets. Addressing these challenges is crucial for harnessing the full potential of Big Data in various industries and fields.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 The Evolution of Big Data Technologies: Past, Present, and Future
The Evolution of Big Data Technologies: Past, Present, and Future
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 The Role of MongoDB in Big Data Analytics
The Role of MongoDB in Big Data Analytics