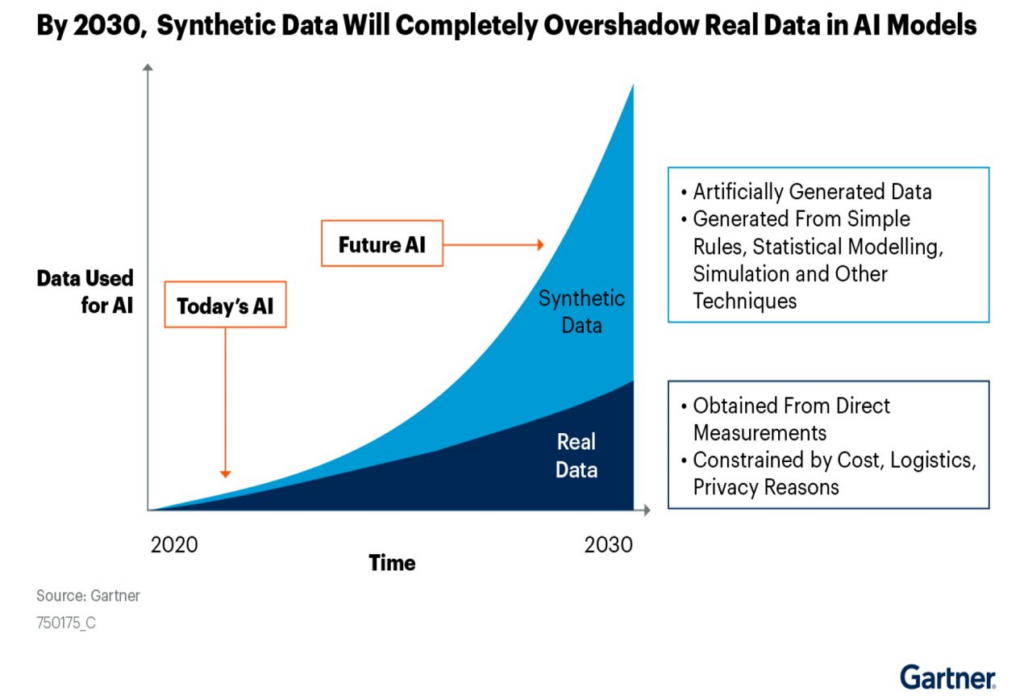
In the realm of Big Data analytics, the emergence of AI-generated synthetic data is revolutionizing the way organizations harness and leverage vast datasets for enhanced insights and decision-making. This cutting-edge technology offers a promising glimpse into the future of data generation, providing a scalable and efficient solution to address data scarcity and privacy concerns. By simulating realistic data scenarios, AI-generated synthetic data enables businesses to perform advanced analytics and machine learning tasks without compromising sensitive information. As we delve deeper into the era of Big Data, the integration of AI-generated synthetic data is poised to play a pivotal role in driving innovation and unlocking the full potential of data-driven decision-making processes.
Understanding Synthetic Data
Synthetic data refers to data that is artificially generated rather than obtained by direct measurement. With the continual rise of Big Data analytics, synthetic data is becoming increasingly important due to its ability to bypass various real-world challenges, including data availability, privacy concerns, and compliance issues. Synthetic data can mimic the statistical properties of real datasets, allowing it to fit seamlessly into many machine learning models.
The Role of AI in Synthetic Data Generation
The evolution of artificial intelligence (AI) plays a pivotal role in the generation of synthetic data. AI algorithms, particularly those based on machine learning and deep learning, can learn from existing data and create new datasets that maintain the characteristics of the original dataset without compromising sensitive information.
These AI models employ generative techniques, such as Generative Adversarial Networks (GANs) and variational autoencoders (VAEs). GANs, for example, work by having two neural networks contesting with each other, allowing for the generation of data that closely resembles the training data while still being entirely synthetic.
Benefits of AI-Generated Synthetic Data
1. Addressing Data Scarcity
One of the most significant challenges in Big Data analytics is the scarcity of high-quality data. Businesses often struggle to obtain enough data to train their machine learning models effectively. AI-generated synthetic data can bridge this gap by producing additional datasets that can be used for training, validation, and testing purposes, ultimately enhancing model performance.
2. Enhancing Privacy and Compliance
With increasing regulations around data privacy, such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), the use of real data poses risks. Synthetic data can be utilized to generate datasets that do not contain any personally identifiable information (PII), allowing organizations to leverage data for analytics without infringing on privacy laws.
3. Cost-Effectiveness
Collecting and processing real data can be a costly and time-consuming endeavor. By generating synthetic datasets, organizations can significantly reduce operational costs associated with data acquisition. This also accelerates the time-to-market for AI-driven products and services.
4. Improving Data Diversity
AI-generated synthetic data can help counteract the biases present in real datasets. By creating diverse datasets, organizations can train their AI models to be more inclusive and equitable, thus improving the overall accuracy and effectiveness of their analytics.
Applications of Synthetic Data in Big Data Analytics
1. Healthcare
The healthcare industry has been rapidly adopting synthetic data to improve patient privacy while conducting research and testing new treatments. By generating synthetic patient records, organizations can analyze trends and patterns without compromising sensitive patient information. For instance, researchers can create realistic datasets to simulate patient responses in drug trials, ensuring comprehensive analysis.
2. Financial Services
In the financial sector, synthetic data is utilized to create training datasets for fraud detection algorithms, risk assessment models, and compliance monitoring systems. By simulating various financial scenarios, organizations can robustly test their models against diverse conditions, ultimately improving their fraud detection accuracy and responsiveness.
3. Autonomous Vehicles
The development of autonomous vehicles heavily relies on the processing of vast amounts of data from sensors and cameras. By employing AI-generated synthetic data, automotive companies can simulate various driving conditions to test their algorithms. This allows manufacturers to improve safety features without the risks associated with real-world testing.
4. Retail and Marketing
Retail businesses can use synthetic data to enhance customer segmentation and predictive analytics. By simulating customer behavior and preferences, retailers can optimize their marketing strategies and customize offers for different customer profiles, resulting in improved engagement and conversion rates.
The Challenges Facing Synthetic Data Technology
1. Quality and Validity of Data
Despite the numerous advantages, the effectiveness of synthetic data is closely tied to its quality. If the trained AI models do not adequately capture the relationships within the original datasets, the resulting synthetic data may be less valid or potentially misleading.
2. Acceptance in the Industry
While many organizations are beginning to adopt synthetic data, there is still skepticism within certain sectors regarding its usability. Overcoming this skepticism will require demonstrating the reliability and accuracy of AI-generated datasets compared to real-world data.
3. Developing Robust Standards
The lack of consistent standards for generating and validating synthetic data poses challenges for widespread adoption. The industry needs to establish best practices and guidelines to ensure that synthetic data can be assessed on its appropriateness for various applications.
The Future Landscape of Synthetic Data in Big Data Analytics
The future of AI-generated synthetic data in Big Data analytics looks promising. As organizations increasingly recognize the value of synthetic datasets in driving innovation and supporting AI models, investment in research and technology will likely grow. Furthermore, advancements in algorithmic efficiency and computational power will lead to even more realistic synthetic data generation methods.
Moreover, the integration of synthetic data with other emerging technologies such as blockchain can enhance data security and integrity, making it easier to manage synthetic datasets within an ecosystem that demands compliance and privacy.
Conclusion
As AI-generated synthetic data continues to evolve, its role in Big Data analytics will be significant. Organizations that embrace this technology will likely gain a competitive edge by leveraging the advantages of synthetic data while navigating the complexities of data privacy and compliance. As the industry matures, the reliance on high-quality synthetic datasets will become a cornerstone of successful data-driven initiatives.
The future of AI-generated synthetic data in big data analytics holds great promise for expanding the scope and capabilities of data-driven insights. With advances in AI technology, synthetic data presents a valuable tool for addressing data privacy concerns, overcoming data scarcity limitations, and enhancing the efficiency of big data analytics processes. Embracing AI-generated synthetic data has the potential to revolutionize how organizations analyze and derive insights from large datasets, driving innovation and competitive advantage in the realm of big data analytics.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data