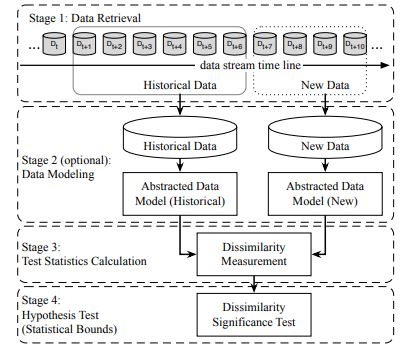
Model drift detection is a critical aspect of maintaining the accuracy and effectiveness of machine learning models in large-scale Big Data systems. As data evolves over time in these dynamic environments, machine learning models can become outdated and lose their predictive power. Detecting model drift is essential for ensuring that models continue to perform optimally and make accurate predictions. This process involves monitoring data distribution shifts, model performance metrics, and other related indicators to identify when a model may need to be retrained or updated. By promptly detecting and addressing model drift, organizations can leverage the full potential of their Big Data systems and make well-informed decisions based on reliable predictive analytics.
In the realm of big data, the advancement of machine learning models has revolutionized the way organizations analyze and interpret vast datasets. However, as new data flows continuously into these systems, the performance of these models can degrade over time. This phenomenon is known as model drift. Detecting and managing model drift is critical for maintaining the accuracy and reliability of predictive analytics in large-scale environments. This article explores the significance of model drift detection in big data systems and provides insights into its implications for businesses.
Understanding Model Drift
Model drift occurs when a trained machine learning model begins to produce less accurate predictions due to changes in the underlying data patterns. There are typically two types of model drift:
- Covariate Shift: This happens when the distribution of the input data changes over time while the underlying relationship between the input and output stays the same.
- Concept Drift: This refers to changes in the relationship between input data and the output variable, meaning the model itself may have to adapt to new patterns in the data.
Both types of drift can significantly impact the predictive power of a model, making it essential to implement systems for detecting these shifts promptly.
Why Model Drift Detection Matters
In large-scale big data systems, where data is constantly streaming, the importance of model drift detection cannot be overstated. Here are some key reasons:
1. Maintaining Prediction Accuracy
Initially trained models may perform adequately based on historical data. However, as new data is ingested, the model may become obsolete. By implementing drift detection mechanisms, organizations can identify shifts in data distribution and rectify the model before significant errors occur.
2. Enhancing Decision-Making
Organizations rely on the insights generated from machine learning models to make critical business decisions. If a model is drifting and not effectively monitored, it can lead to erroneous conclusions that could have far-reaching consequences, affecting everything from marketing strategies to operational efficiencies.
3. Reducing Operational Costs
Detecting and managing model drift can help mitigate costs associated with poor model performance. Incorrect predictions can lead to wasted resources, whether that’s in customer mis-targeting, supply chain disruptions, or unyielded revenue due to missed opportunities.
4. Boosting Customer Trust
Consumers today expect accurate and personalized services. If predictive models fail to deliver relevant outcomes, customer trust may decrease. By consistently monitoring for drift and retraining models when necessary, organizations can ensure they meet user expectations, thus fostering trust and loyalty.
5. Compliance and Risk Management
Many industries are subject to regulatory frameworks that dictate the performance of predictive models (e.g., finance and healthcare). Ensuring that models remain compliant with these regulations requires rigorous drift detection and adaptation strategies to avoid legal repercussions.
Strategies for Model Drift Detection
There are several strategies organizations can employ to detect model drift in big data systems effectively:
1. Statistical Monitoring
Statistical techniques can be applied to continuously monitor the performance of models. Metrics such as AUC (Area Under the Curve), precision, and recall can be tracked to identify signs of drift. If model performance drops below a predetermined threshold, it serves as an alert for potential drift.
2. Data Visualization
Visual tools can illustrate changes in data distributions over time. Graphical representations of input feature distributions can help data scientists quickly identify anomalies or shifts, facilitating timely interventions.
3. Use of Monitoring Libraries
Various open-source libraries and tools have emerged to provide drift detection functionalities. Libraries such as Alibi Detect and Evidently offer pre-built functions to help in monitoring model performance and detecting drift efficiently.
4. Regular Model Evaluation
Establishing a routine for model evaluation that checks both model performance and data consistency can aid in identifying drift early. Regularly retraining models on the latest data can also help maintain relevance and accuracy in predictions.
5. Setting Alert Systems
Triggering alerts based on specific performance metrics can automate the drift detection process. Automatic notifications can prompt data scientists or engineers to investigate issues immediately, speeding up the identification and correction of model drift.
Challenges in Model Drift Detection
While detecting model drift is crucial, it comes with its own set of challenges:
1. Real-Time Data Processing
Large-scale big data systems often deal with real-time data streams, making it challenging to monitor model performance continuously. Implementing effective drift detection requires advanced processing capabilities to handle data velocity alongside volume.
2. False Positives
A common issue is the occurrence of false positives when detecting drift, leading to unnecessary retraining and resource allocation. Balancing sensitivity and specificity in drift detection mechanisms is vital to ensure efficient operations.
3. Complexity of Feature Interactions
In complex models, particularly those utilizing high-dimensional datasets, determining the precise cause of drift can be intricate. Understanding how multiple features interact over time requires sophisticated analytical techniques.
Implementing a Robust Drift Detection Framework
To effectively combat model drift, businesses should develop a structured framework that incorporates various processes:
1. Define Goals and Metrics
Establish clear goals regarding model performance and include specific success metrics that will guide your drift detection efforts.
2. Build a Data Pipeline
Design an efficient data pipeline that allows for the constant feeding of new data into the model while enabling real-time monitoring for performance evaluation.
3. Invest in Technology
Utilizing cloud-based solutions for scalability and employing technologies like Apache Kafka for live data processing can enhance drift detection capabilities.
4. Foster a Culture of Continuous Improvement
Encouraging teams to adopt a mindset geared towards constant learning and adaptation can enhance the overall effectiveness of drift detection systems. Regular training and updates can uplift a team’s ability to detect and respond quickly to model drift.
5. Prioritize Documentation and Communication
Having comprehensive documentation on detection strategies, model performance evaluations, and response plans can ensure that any team member can mitigate issues swiftly. Open communication lines facilitate collaborative problem-solving during instances of drift.
The significance of model drift detection within large-scale big data systems is undeniable. By prioritizing this practice, organizations can maintain model performance, enhance decision-making, and secure their investment in machine learning initiatives. As big data continues to expand and evolve, staying ahead of model drift will remain a critical aspect of effective data-driven strategies.
The detection of model drift in large-scale Big Data systems is crucial for ensuring the accuracy and reliability of machine learning models over time. By monitoring and adapting to changes in data patterns, organizations can make informed decisions and maintain optimal performance in their data-driven applications. Model drift detection plays a key role in safeguarding the integrity of predictive analytics and ultimately contributes to the success of Big Data initiatives.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 How Big Data Powers Machine Learning Models
How Big Data Powers Machine Learning Models
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works
 The Impact of Big Data on Financial Services and Banking
The Impact of Big Data on Financial Services and Banking