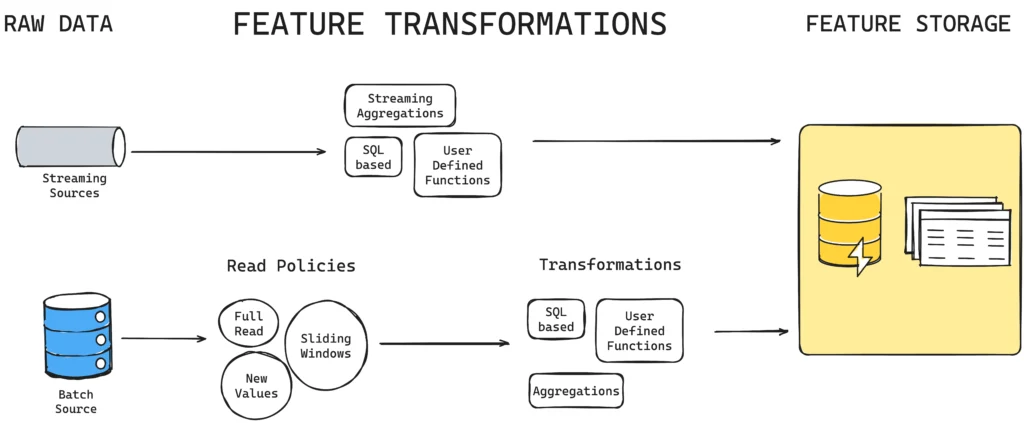
In the realm of Big Data, the effective utilization of AI-powered feature engineering has become a critical component in optimizing large-scale data pipelines. Feature engineering involves the process of transforming raw data into meaningful features that can improve the performance of machine learning models. By leveraging artificial intelligence techniques, such as natural language processing and deep learning, organizations can extract valuable insights from vast datasets with greater efficiency and accuracy. This integration of AI-powered feature engineering in data pipelines not only enhances data processing capabilities but also enables businesses to uncover hidden patterns and trends that can drive informed decision-making.
In the realm of Big Data, the significance of feature engineering cannot be overstated. Feature engineering is the process of using domain knowledge to select, modify, or create variables that enhance the performance of machine learning models. In recent years, the advent of artificial intelligence (AI) has revolutionized this area, leading to the rise of AI-powered feature engineering. This article explores how AI is transforming feature engineering in large-scale data pipelines.
Understanding Feature Engineering in Big Data
Feature engineering involves systematic processes that transform raw data into informative and useful features for machine learning algorithms. In large-scale data pipelines, the volume, variety, and velocity of data present unique challenges:
- Volume: The sheer size of big data can make traditional feature engineering techniques inefficient.
- Variety: Data comes from various sources, necessitating tailored feature extraction methods.
- Velocity: The fast pace at which data is generated requires real-time feature engineering solutions.
AI-powered techniques provide robust solutions to these challenges, automating and optimizing the feature engineering process.
AI Techniques Enhancing Feature Engineering
Several AI techniques are at the forefront of advancing feature engineering in big data applications, including:
1. Automated Feature Extraction
One of the significant innovations brought by AI is the capability for automated feature extraction. By leveraging algorithms such as Deep Learning, AI can learn patterns and extract features from unstructured data, like images and text, without extensive human intervention.
For instance, in image classification tasks, convolutional neural networks (CNNs) can identify relevant features such as edges, textures, and shapes automatically, significantly speeding up the feature engineering process.
2. Recursive Feature Elimination
Recursive feature elimination (RFE) is a machine learning technique that helps to select important features from a dataset. AI algorithms can automate the process of removing less important features, thus optimizing model performance while reducing computational load.
This automated selection process is particularly important in large datasets, where variables can be numerous and complex, allowing data scientists to focus on the most impactful features.
3. Embedding Techniques
Embedding techniques, such as word embeddings (Word2Vec, GloVe) in natural language processing, enable the transformation of categorical variables into numerical formats, which are essential for machine learning algorithms. AI models can identify relationships and similarities between different categories, providing enhanced embeddings that capture the underlying context.
4. Feature Construction
AI-driven approaches enable the automatic construction of new features from existing ones. Techniques such as genetic algorithms or neural architecture search can dynamically create features based on various combinations of input data. This not only improves the richness of the features but also ensures that the features are tailored to the specific patterns in the data.
Integration of AI in Large-Scale Data Pipelines
Integrating AI-powered feature engineering into large-scale data pipelines involves multiple components:
1. Data Collection and Storage
Data pipelines must be designed to efficiently handle massive datasets. Tools like Apache Kafka for real-time data processing and Apache Hadoop for distributed storage are essential for managing this influx of data. The AI-powered feature engineering processes can be integrated at various points along the pipeline, pulling data from these sources automatically.
2. Data Preprocessing
Before applying AI algorithms, data preprocessing is critical to ensure accuracy and efficiency. This step includes data cleaning, normalization, and transformation, ensuring that the data fed into AI models is of the highest quality. For instance, the removal of outliers and filling in missing values can significantly enhance model performance.
3. Model Training
Once features have been engineered, the next step involves training machine learning models. This is where AI excels; it can evaluate multiple model architectures and hyperparameters to optimize performance effectively.
4. Real-time Feature Engineering
In dynamic environments, where data is constantly evolving, real-time feature engineering is vital. By utilizing AI algorithms, it’s possible to continuously learn and adapt features from new data, ensuring that models retain their accuracy over time. Streaming analytics tools, such as Apache Flink, facilitate this process by allowing real-time data processing and model updates.
Challenges and Solutions in AI-Powered Feature Engineering
Despite the numerous advantages of AI-powered feature engineering, several challenges remain:
1. Data Quality
The effectiveness of AI algorithms is heavily dependent on the quality of the data. Poor quality data with inaccuracies can lead to misleading features and, consequently, unreliable models. Ensuring robust preprocessing methods can mitigate these issues and enhance model reliability.
2. Interpretability
AI models, particularly deep learning architectures, can be seen as black boxes, making it challenging to interpret how features are derived. Applying techniques like SHAP values or LIME can provide insights into the importance and impact of various features, enhancing the model’s transparency.
3. Scalability
As datasets grow, ensuring that feature engineering processes scale effectively is paramount. Utilizing cloud computing services such as Amazon Web Services (AWS) or Google Cloud Platform (GCP) allows for flexible scaling of resources as data volumes increase, enabling AI-powered feature engineering to keep pace with demand.
The Future of AI-Powered Feature Engineering in Big Data
As we look ahead, the role of AI in feature engineering within big data ecosystems will only expand. With advances in transfer learning and federated learning, models will demonstrate greater adaptability and efficiency in feature extraction, benefitting industries across the spectrum, from healthcare to finance.
Furthermore, the integration of AI with emerging technologies like Internet of Things (IoT) will lead to more sophisticated feature engineering methods tailored to real-time data streams, enriching the predictive capabilities of models.
Conclusion
AI-powered feature engineering is not just a trend; it is a pivotal development in the evolution of data science, particularly for large-scale data environments. The automation, optimization, and real-time capabilities offered by AI are critical in harnessing the full potential of big data, leading to more accurate and efficient machine learning solutions. Organizations that embrace AI-driven feature engineering will gain a significant competitive edge, allowing for better decision-making and enhanced operational efficiency.
The integration of AI-powered feature engineering within large-scale data pipelines offers unparalleled advantages in maximizing the efficiency, accuracy, and scalability of Big Data operations. By automating the process of extracting relevant features from raw data, AI technology facilitates streamlined decision-making and enables businesses to derive valuable insights from complex datasets at an unprecedented pace. Embracing AI-powered feature engineering is crucial for organizations looking to harness the full potential of Big Data and maintain a competitive edge in today’s data-driven landscape.
Related posts:
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 The Intersection of Big Data and Artificial Intelligence
The Intersection of Big Data and Artificial Intelligence
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Real-Time AI and Big Data: How It Works
Real-Time AI and Big Data: How It Works
 The Impact of Big Data on Financial Services and Banking
The Impact of Big Data on Financial Services and Banking
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges