Apache Beam is an open-source, unified programming model designed to simplify and accelerate large-scale data processing tasks in the realm of Big Data analytics. By offering a versatile and flexible framework that supports a variety of data processing and streaming capabilities, Apache Beam serves as a bridge between different Big Data processing engines, allowing developers to write code that can be executed on various platforms without the need for major modifications. This seamless interoperability and portability make Apache Beam a key player in enabling organizations to harness the power of Big Data efficiently and effectively for complex data processing tasks.
In the ever-evolving landscape of Big Data, organizations are constantly seeking methods to streamline their data processing pipelines. Apache Beam has emerged as a powerful tool for achieving unified big data processing across various sources and sinks. This article delves into the key features of Apache Beam, its architecture, use cases, and how it integrates with other platforms for seamless data handling.
What is Apache Beam?
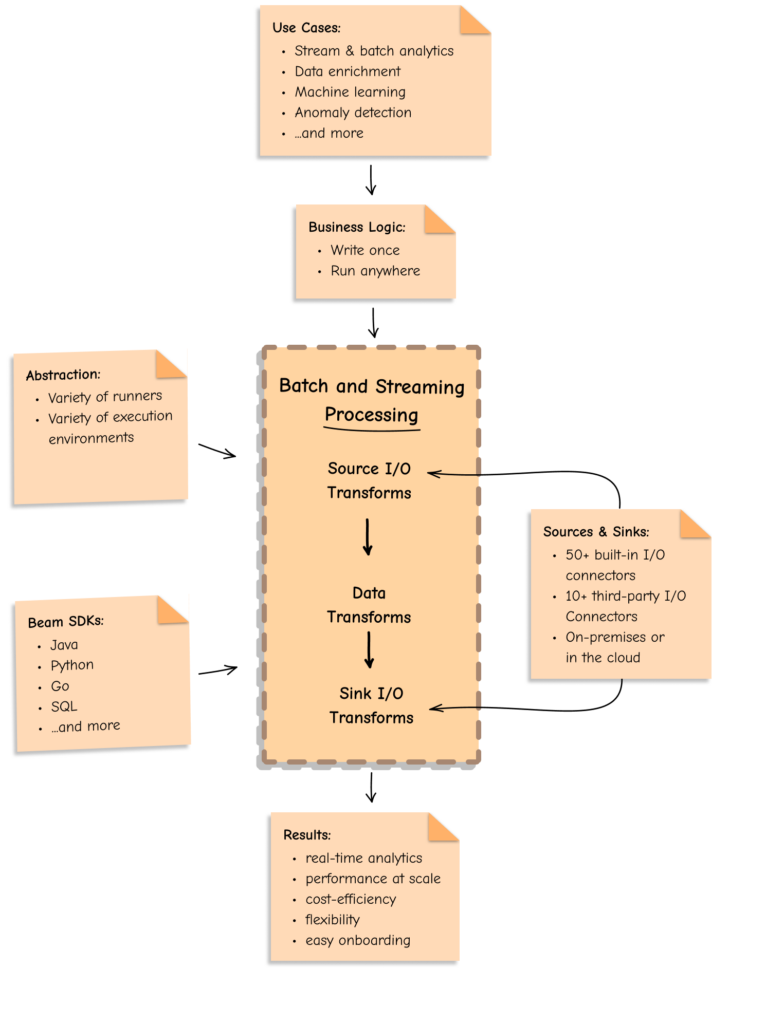
Apache Beam is an open-source, unified model for defining data processing workflows. It allows developers to create batch and streaming data processing applications that can be run on various execution engines, popularly known as runners. The beauty of Beam lies in its versatility; it abstracts the underlying execution environment, enabling data engineers to focus on writing data processing logic rather than worrying about the infrastructure.
The Architecture of Apache Beam
The architecture of Apache Beam consists of three major components:
- SDKs: Beam supports multiple languages, including Java, Python, and Go, allowing developers to write the data processing logic in their preferred language.
- Transformations: Beam provides a rich set of predefined transformations, such as map, filter, and groupByKey, which simplify the task of manipulating data.
- Runners: The actual execution of Beam pipelines happens through various runners like Apache Flink, Apache Spark, Google Cloud Dataflow, and others. Each of these runners optimally executes the data processing logic.
Unified Batch and Streaming Processing
Traditionally, organizations had to maintain separate systems for processing batch and streaming data. Apache Beam eliminates this need by allowing developers to write code that is agnostic to the data processing mode. This means that the same pipeline can handle both batch and streaming input seamlessly.
For example, a business might want to analyze user activity data from a website in real-time while also generating daily reports from historical records. With Apache Beam, developers can create a unified processing model that accommodates both requirements without duplicating code or using different frameworks.
Key Features of Apache Beam
1. Flexibility
Apache Beam’s flexibility allows it to work with various data sources and sinks, including databases, cloud storage, and message queues. This feature enables organizations to integrate diverse data streams without extensive reconfiguration.
2. Portability
One of the standout features of Apache Beam is its portability. The same pipeline code can be executed on any supported runner, saving time and effort in redeveloping code for different environments. This characteristic is particularly useful for organizations that leverage multiple cloud providers or hybrid architectures.
3. Rich Set of APIs
Beam provides a comprehensive API that allows for easy data manipulation and transformation. From simple data filtering to advanced windowing techniques, the API caters to both novice and seasoned developers.
4. Event Time Processing
Processing data based on the event time rather than the processing time is critical in many real-time applications. Beam’s built-in windowing and triggers support allows developers to manage late data and perform computations effectively.
5. Scalability and Fault Tolerance
With the ability to leverage the underlying runner’s capabilities, Apache Beam pipelines can scale to handle large data volumes efficiently. Moreover, it provides fault tolerance features automatically, allowing reliable processing and recovery mechanisms.
Use Cases for Apache Beam
Apache Beam is increasingly being adopted across various industries for different use cases. Here are some notable examples:
1. Real-time Analytics
Organizations can utilize Apache Beam to analyze streaming data in real time, offering insights into user behavior, system performance, and other metrics. For instance, an e-commerce platform can track customer interactions and personalize recommendations instantly.
2. Data Ingestion and ETL
Beam effectively handles Extract, Transform, Load (ETL) processes, making it easier to transfer data from various sources to a data warehouse or data lake. Its ability to manage both batch and streaming data allows organizations to modernize their data pipelines efficiently.
3. Event-Driven Architectures
With the rise of microservices and event-driven architectures, Beam plays a crucial role in processing events as they occur and triggering downstream actions based on event conditions.
4. Data Transformation and Enrichment
Data quality and relevance are paramount, and Apache Beam excels in transforming and enriching datasets. This includes cleaning data, augmenting it with additional attributes, or aggregating it for reporting.
Integrating Apache Beam with Other Big Data Tools
Apache Beam is not a standalone tool but rather functions best when integrated with other Big Data technologies. Some notable integrations include:
1. Apache Kafka
Apache Kafka serves as a robust messaging system that complements Beam in streaming data applications. Using Beam’s rich Kafka connector, developers can consume and produce data streams for further processing.
2. Apache Flink and Spark
When it comes to executing data processing pipelines, Beam can leverage Apache Flink or Apache Spark as runners. These platforms provide powerful data processing capabilities, making them ideal for running Beam pipelines at scale.
3. Google Cloud Dataflow
Google Cloud Dataflow, developed by Google, is designed to execute Apache Beam pipelines without requiring any setup of execution infrastructure. It automates resource management, scaling, and load balancing for optimal performance.
Getting Started with Apache Beam
To get started with Apache Beam, developers can follow these steps:
1. Install Apache Beam
Depending on the programming language, installation varies. For instance, you can install the Python SDK using pip:
pip install apache-beam2. Define a Pipeline
Start by importing necessary libraries and defining your data transformations. Here’s a simple example in Python:
import apache_beam as beam
with beam.Pipeline() as pipeline:
(pipeline
| 'ReadData' >> beam.io.ReadFromText('input.txt')
| 'TransformData' >> beam.Map(lambda x: x.upper())
| 'WriteData' >> beam.io.WriteToText('output.txt'))
3. Choose a Runner
Select a runner based on your infrastructure and scalability needs. For local testing, you can use the DirectRunner, while for production workloads, consider DataflowRunner or FlinkRunner.
Challenges and Considerations
While Apache Beam offers numerous advantages, there are challenges to consider:
1. Learning Curve
Though Apache Beam provides a user-friendly API, understanding the intricacies of its architecture and runtime behavior may require time and experience.
2. Performance Optimization
Optimizing Beam pipelines for performance requires an understanding of how different runners handle resource allocation, data shuffling, and parallelization. Organizations should run performance benchmarks to identify the best configurations for their needs.
3. Community and Support
As an open-source project, the level of community support may vary. Developers may benefit from active participation in forums and contributions to ensure continual learning and improvements.
Conclusion
Apache Beam is paving the way for unified big data processing by providing flexibility, scalability, and ease of integration with existing Big Data technologies. Its capability to process both streaming and batch data under a single framework is a game-changer for many organizations looking to enhance their data strategy. As enterprises increasingly adopt more sophisticated data architectures, embracing tools like Apache Beam will become essential for anyone in the Big Data landscape.
Apache Beam plays a critical role in enabling unified big data processing by providing a versatile and unified programming model that can seamlessly execute across multiple distributed processing frameworks. Its flexibility, scalability, and abstraction layer for data processing tasks make it a valuable tool for organizations seeking to streamline their big data processing workflows and leverage the power of diverse data sources efficiently. With Apache Beam, companies can achieve greater efficiency, scalability, and agility in processing large volumes of data, ultimately unlocking valuable insights and driving data-driven decision-making.
Related posts:
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Introduction to NoSQL Databases for Big Data
Introduction to NoSQL Databases for Big Data
 Understanding HBase: How it Works in the Hadoop Ecosystem
Understanding HBase: How it Works in the Hadoop Ecosystem
 Natural Language Processing (NLP) with Big Data
Natural Language Processing (NLP) with Big Data
 How Big Data is Used in Deep Learning Applications
How Big Data is Used in Deep Learning Applications
 Sentiment Analysis with Big Data and AI
Sentiment Analysis with Big Data and AI
 Big Data in Smart Cities: Applications and Challenges
Big Data in Smart Cities: Applications and Challenges
 Big Data and Retail: How It’s Changing the Shopping Experience
Big Data and Retail: How It’s Changing the Shopping Experience
 Big Data in Agriculture: Precision Farming and Analytics
Big Data in Agriculture: Precision Farming and Analytics
 What is Predictive Analytics in Big Data?
What is Predictive Analytics in Big Data?
 Data Science vs. Big Data Analytics: Key Differences
Data Science vs. Big Data Analytics: Key Differences
 Data Partitioning Strategies for Big Data Scalability
Data Partitioning Strategies for Big Data Scalability
 The Importance of Data Governance in Big Data
The Importance of Data Governance in Big Data