In the realm of Big Data analytics, where the volume and complexity of data continue to grow exponentially, model compression emerges as a crucial technique to optimize the efficiency and performance of machine learning models. Among various methods employed for model compression, Knowledge Distillation has gained significant attention for its ability to reduce the size and computational requirements of Big Data models while maintaining their accuracy and generalization capabilities. This article explores the role of Knowledge Distillation in the context of Big Data, highlighting its impact on accelerating data processing, enhancing scalability, and improving resource utilization in modern data-driven environments.
In the era of Big Data, the demand for efficient, scalable, and performant machine learning models has dramatically increased. As organizations amass and analyze vast amounts of data, the computational resources required to process this information can be enormous. One of the key strategies that have emerged to address this challenge is knowledge distillation. This article delves into the significance of knowledge distillation in the realm of Big Data model compression, examining its principles, methodologies, and impact.
What is Knowledge Distillation?
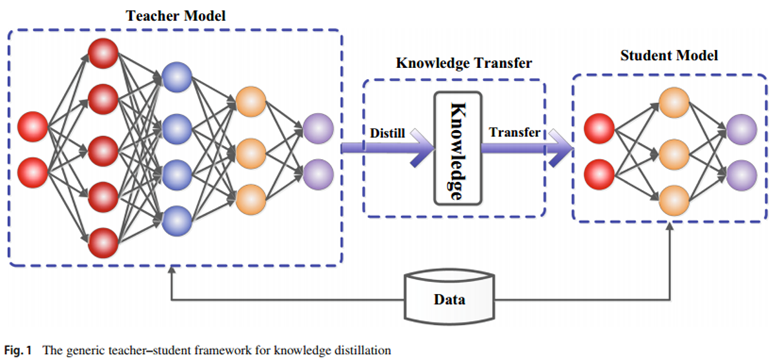
Knowledge distillation is a techniques in machine learning where a smaller, more efficient model (the student model) is trained to replicate the behavior of a larger, more complex model (the teacher model). The underlying idea is to transfer knowledge from the teacher to the student, enabling the student to generalize effectively while significantly reducing computational requirements.
By leveraging the strengths of deep learning architectures, knowledge distillation allows practitioners to refine their models for faster inference times and lower resource usage without sacrificing performance. This becomes particularly valuable in Big Data scenarios, where processing speed and resource optimization are crucial.
The Need for Model Compression in Big Data
As data sources continue to multiply, the complexity of machine learning models invariably increases. Such models often consist of billions of parameters and require substantial computational power for training and inference. Consequently, deploying these models in production can be costly and impractical.
Big Data ecosystems demand solutions that optimize both training and inference, making it essential to use techniques such as model compression. Model compression aims to create lower-complexity versions of models while striving to maintain accuracy. Knowledge distillation serves as a pivotal technique within this undertaking.
How Knowledge Distillation Works
The process of knowledge distillation typically involves the following steps:
- Training the Teacher Model: Begin by training a large, complex model on a particular task using the available Big Data.
- Generating Soft Targets: After the teacher model has been trained, it generates predictions (often referred to as soft targets) for the training data. These soft targets differ from hard labels as they retain richer information about the inter-class relationships.
- Training the Student Model: A smaller model is then trained using the soft targets generated by the teacher. The student is encouraged to learn not only the correct class but also the confidence levels associated with each class prediction.
- Fine-tuning and Deployment: Post-training, the student model may undergo fine-tuning on the hard labels before deployment in real-world applications.
Benefits of Knowledge Distillation for Big Data Model Compression
Implementing knowledge distillation in Big Data contexts offers several advantages:
1. Reduced Model Size
Knowledge distillation can significantly shrink the size of machine learning models. As larger models often contain redundant architectures and parameters, distilling this knowledge leads to a streamlined version that consumes less memory and storage space, crucial for on-device processing in Big Data applications.
2. Faster Inference Times
In many use cases, the speed of predictions is paramount. Knowledge distillation results in smaller models that are capable of making inferences much more quickly than their larger counterparts. This speed improvement is critical in applications involving real-time data analysis, such as fraud detection and online recommendations.
3. Energy Efficiency
Running large neural networks requires substantial computational power, leading to increased energy costs. Smaller models derived from knowledge distillation allow organizations to reduce energy consumption, aligning with growing environmental concerns and regulatory pressures.
4. Scalability
In a Big Data context, scalability becomes vital. Knowledge distilled models are easier to deploy across various devices and systems, maintaining performance while being less resource-intensive. This scalability enables businesses to expand their machine learning applications without being hampered by infrastructural limitations.
5. Preserved or Improved Accuracy
While concerns about model size often lead to compromises in accuracy, knowledge distillation can help retain or even improve the predictive performance of smaller models. By learning from the rich outputs of the teacher model, students can capture complex patterns that would otherwise be overlooked in traditional training.
Applications of Knowledge Distillation in Big Data
Given the advantages of knowledge distillation, numerous applications have emerged in the field of Big Data.
1. Natural Language Processing (NLP)
NLP models, particularly those utilizing deep learning architectures like transformers, can be immensely resource-heavy. Knowledge distillation allows for the development of lighter models that can operate in real-time, making it feasible to deploy complex language models on mobile devices, which is particularly useful for chatbots and virtual assistants.
2. Computer Vision
In computer vision tasks, such as image classification and object detection, knowledge distillation aids in creating lightweight models suitable for edge devices. These devices often operate under resource constraints while still needing advanced image processing capabilities.
3. Autonomous Systems
In autonomous vehicles, where quick decision-making is crucial, using distilled models can improve responsiveness. The efficiency gained from knowledge distillation contributes significantly, enabling faster processing of sensory data while maintaining accuracy in predictions.
4. Internet of Things (IoT)
IoT devices generate massive quantities of data but are often limited in terms of hardware resources. Knowledge distillation facilitates deploying AI models that can run on these devices effectively, exploiting the underlying data while still providing valuable insights.
Challenges and Considerations
While knowledge distillation offers numerous advantages, it’s essential to consider certain challenges:
1. Selection of Teacher Model
The performance of the student model is highly dependent on the teacher model’s quality. Selecting an inappropriate teacher model can lead to suboptimal outcomes, emphasizing the need for careful consideration in model selection.
2. Parameter Tuning
Successfully applying knowledge distillation often requires adjusting various hyperparameters, such as the temperature used in the softmax function during the generation of soft targets. Finding the optimal configuration can be nuanced and time-consuming.
3. Dataset Diversity
Knowledge distillation works best when the teacher and student models are trained on representative datasets. If the dataset lacks diversity, the distilled model might not generalize well to unseen data, undermining its effectiveness in Big Data applications.
Future Directions in Knowledge Distillation
As the field of AI and machine learning evolves, so too will the techniques surrounding knowledge distillation. Future research may focus on:
- Innovative Architectures: Developing new model architectures that emphasize easier knowledge transfer.
- Dynamic Distillation: Implementing adaptive knowledge distillation techniques that evolve based on changing data.
- Ensemble Techniques: Combining multiple teacher models to enhance the student learning experience.
The integration of knowledge distillation in Big Data model compression promises to revolutionize how organizations interact with and leverage large datasets, ultimately shaping the next generation of machine learning applications.
Knowledge distillation plays a vital role in compressing big data models by transferring knowledge from complex teacher models to simpler student models, enabling efficient computation and storage management in the context of big data applications.
Related posts:
 What is Big Data? A Beginner’s Guide
What is Big Data? A Beginner’s Guide
 The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
The Five Vs of Big Data: Volume, Velocity, Variety, Veracity, and Value
 Structured vs. Unstructured Data: Key Differences and Examples
Structured vs. Unstructured Data: Key Differences and Examples
 The Role of Data Warehousing in Big Data
The Role of Data Warehousing in Big Data
 What is a Data Lake? Definition, Uses, and Benefits
What is a Data Lake? Definition, Uses, and Benefits
 Introduction to Distributed Computing in Big Data
Introduction to Distributed Computing in Big Data
 Big Data vs. Traditional Data: What’s the Difference?
Big Data vs. Traditional Data: What’s the Difference?
 Understanding Data Pipelines in Big Data
Understanding Data Pipelines in Big Data
 The Evolution of Big Data Technologies: Past, Present, and Future
The Evolution of Big Data Technologies: Past, Present, and Future
 Data Ingestion Techniques for Big Data Processing
Data Ingestion Techniques for Big Data Processing
 What is Apache Hadoop? A Complete Guide
What is Apache Hadoop? A Complete Guide
 Understanding Apache Spark: Features and Use Cases
Understanding Apache Spark: Features and Use Cases
 What is Kafka? How it Powers Real-Time Big Data Applications
What is Kafka? How it Powers Real-Time Big Data Applications
 Apache Flink vs. Apache Spark: Which One is Better?
Apache Flink vs. Apache Spark: Which One is Better?